Reopening as the release is not working on the stable branch
Feed Advanced Search
Apr 7 2021
Apr 7 2021
vsellier reopened T3165: Generate historical data from the new counters series as "Work in Progress".
vsellier changed the status of T3215: Deploy the new counters in staging from Open to Work in Progress.
vsellier committed rDCNT4d940936d8f2: Use an intermediate temporary file to generate the historical data (authored by vsellier).
Use an intermediate temporary file to generate the historical data
vsellier closed T3165: Generate historical data from the new counters series, a subtask of T2912: Next generation archive counters, as Resolved.
vsellier committed rDCNTf2fba43f087e: Use an intermediate temporary file to generate the historical data (authored by vsellier).
Use an intermediate temporary file to generate the historical data
vsellier requested review of D5444: Use an intermediate temporary file to generate the historical data.
vsellier committed rDCNT42157fd04885: Allow the webapp to retrieve the history file via a GET endpoint (authored by vsellier).
Allow the webapp to retrieve the history file via a GET endpoint
vsellier updated the diff for D5442: Allow the webapp to retrieve the history file via a GET endpoint.
Register the history endpoint only if the configuration is present
vsellier updated the diff for D5442: Allow the webapp to retrieve the history file via a GET endpoint.
- Return a 404 if the requested file does not exist
- Use a fixture to configure the tests to make them easier to read
vsellier added inline comments to D5442: Allow the webapp to retrieve the history file via a GET endpoint.
vsellier requested review of D5442: Allow the webapp to retrieve the history file via a GET endpoint.
add python3-requests-mock dependency
Manage and expose the historical data
vsellier updated the diff for D5429: Manage and expose the historical data.
update according the review's feedbacks
Add staging environment diagram
vsellier updated the diff for D5429: Manage and expose the historical data.
fix typos on the commit message
Apr 6 2021
Apr 6 2021
vsellier updated the diff for D5429: Manage and expose the historical data.
fix another typo
vsellier requested review of D5429: Manage and expose the historical data.
vsellier closed T3211: staging: git loader can't load repositories hosted by github.com as Resolved.
The requested change was make by the DSI. Everything is working well now.
vsellier committed rDCOREcbc9b86b2336: Allow to use several backends with a RPCServerApp (authored by vsellier).
Allow to use several backends with a RPCServerApp
vsellier added a comment to D5428: Allow to use several backends with a RPCServerApp.
vsellier requested review of D5428: Allow to use several backends with a RPCServerApp.
vsellier added a comment to T3211: staging: git loader can't load repositories hosted by github.com.
The wrong network profile was asked for the staging gateway so it seems it doesn't have a complete access to internet.
A mail was sent to the DSI to request an unfiltered access.
vsellier changed the status of T3211: staging: git loader can't load repositories hosted by github.com from Open to Work in Progress.
Apr 2 2021
Apr 2 2021
vsellier renamed T3194: Upgrade opnsense firewalls from 20.7.4 to 21.1.4 from Upgrade opensense firewalls from 20.7.4 to 21.1.4 to Upgrade opnsense firewalls from 20.7.4 to 21.1.4.
vsellier added a comment to T3194: Upgrade opnsense firewalls from 20.7.4 to 21.1.4.
After solving the problem the upgrade was pretty smooth. The firewall perform the following steps:
- upgrade to the last current minor version of the current major branch
- upgrade to the first minor version of the next major branch
- upgrade to the last minor version ot the current major branch
lgtm
vsellier added a comment to T3194: Upgrade opnsense firewalls from 20.7.4 to 21.1.4.
Before starting the upgrade, we discovered 2 problem we had to fix:
- The backup had no access to internet we block the upgrade
- The master/backup switch was not working for 4 of the 8 VIPs
Apr 1 2021
Apr 1 2021
vsellier changed the status of T3194: Upgrade opnsense firewalls from 20.7.4 to 21.1.4 from Open to Work in Progress.
vsellier closed T3190: counters: Error during directory topic ingestion, a subtask of T2912: Next generation archive counters, as Resolved.
vsellier committed rSPSITE2c2e7ed2403f: counters: allow to consume big messages of the directory topic (authored by vsellier).
counters: allow to consume big messages of the directory topic
vsellier added a comment to D5398: postgresql/client: Fix redundant user entry setup.
Is the user not used for the creation of the pgpass file ?
Update octocatalog-diff facts
vsellier requested review of D5399: counters: allow to consume big messages of the directory topic.
vsellier added a comment to T3190: counters: Error during directory topic ingestion.
vsellier added a comment to T3191: journal-client: Add support of max message size configuration.
The journal client supports dynamic configuration via kwargs so no there is no need to improve it.
vsellier changed the status of T3191: journal-client: Add support of max message size configuration from Open to Work in Progress.
vsellier added a comment to T3190: counters: Error during directory topic ingestion.
It seems the problem is not present anymore with a higher max message size ('500 * 1024 * 1024').
vsellier added a comment to T3190: counters: Error during directory topic ingestion.
for the record, increasing the property message.max.bytes to 100 * 1024 * 1024 in the consumer configuration is not solving the problem
vsellier added a comment to T3190: counters: Error during directory topic ingestion.
The same problem occured during the poc, theses messages were ignored by using this consumer configuration "errors.tolerance": 'all' [1].
I will try to find if there is a more elegant way to deal with this issue ;)
vsellier updated the task description for T3190: counters: Error during directory topic ingestion.
vsellier changed the status of T3190: counters: Error during directory topic ingestion from Open to Work in Progress.
Mar 31 2021
Mar 31 2021
vsellier updated subscribers of T3041: [production] Provision enough space for the search ES cluster to ingest all intrinsic metadata.
After talking with @rdicosmo, we finally chose to replace on each server the 4 HDD 2.4To by 6 SSD 1.9To to be sure we will have good performances and enought space for the future.
The quote wil nowl be sent to the purchasing service according to the usual procedure [1]
Mar 30 2021
Mar 30 2021
vsellier added a project to T3143: Migrate revision metadata to extid in the storage: System administration.
vsellier added a comment to T3041: [production] Provision enough space for the search ES cluster to ingest all intrinsic metadata.
Final quotation sent for approval.
The details are:
3 PowerEdge R6515 (1u) with per server:
- 10 disks enclosure
- BOSS controller with 2 240Go cards (for system)
- 4 SAS 2.5" 10k 2.4To disks
- SFP+ network card
- 2 SFP cables
- 2 power supplies with their cables
- IDRac enterprise
- Rack mount rails with cable management
lgtm
credentials sent by PM
vsellier updated the task description for T3188: staging/journal: create douardda credentials.
vsellier added a comment to T3188: staging/journal: create douardda credentials.
- unprivileged user :
username=swh-douardda password=XXXXX
vsellier changed the status of T3188: staging/journal: create douardda credentials from Open to Work in Progress.
vsellier committed rSPSITE6935f3532507: network: Remove unecessary route between internal network and VLAN1300 (authored by vsellier).
network: Remove unecessary route between internal network and VLAN1300
vsellier updated the diff for D5377: network: Remove unecessary route between internal network and VLAN1300.
rebase
Mar 29 2021
Mar 29 2021
vsellier requested review of D5377: network: Remove unecessary route between internal network and VLAN1300.
Mar 26 2021
Mar 26 2021
explicit a couple of relations
vsellier added a comment to T3165: Generate historical data from the new counters series.
The final counters architecture looks like this with this improvment:
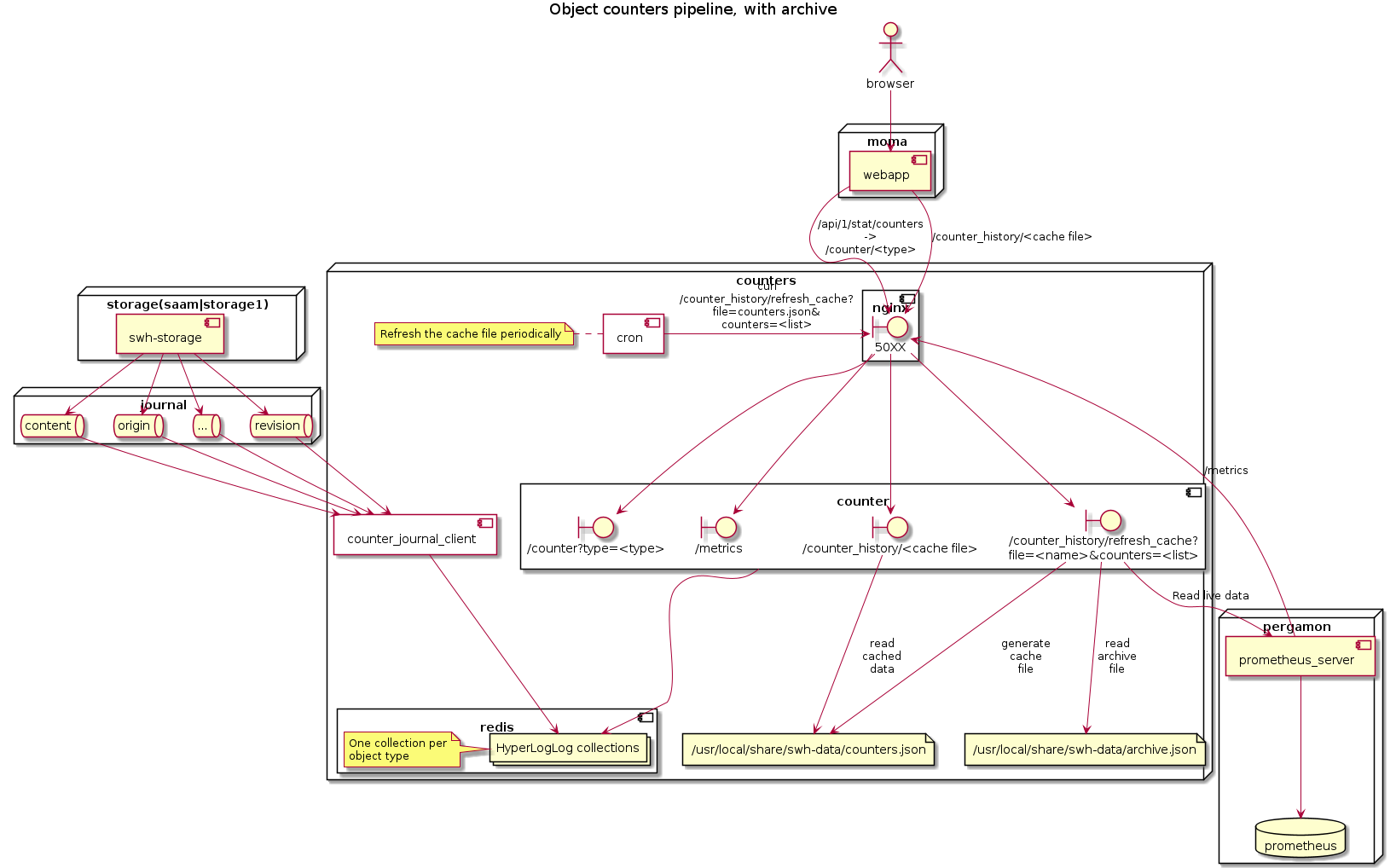
vsellier committed rDSNIPcf77331a0f8f: Upgrade counters architecture to handle the historical data management (authored by vsellier).
Upgrade counters architecture to handle the historical data management
vsellier added a comment to T3165: Generate historical data from the new counters series.
An improvment idea came to me during the refactoring, the script can be splitted and integrated in the 'swh-counters' codebase.
vsellier added inline comments to D5343: docs/sys-info: Update deployment documentation.
lgtm
Mar 25 2021
Mar 25 2021
vsellier added inline comments to D5342: docs/sys-info: Update information and rework sentence phrasing.
vsellier requested changes to D5342: docs/sys-info: Update information and rework sentence phrasing.
node counters1.internal.softwareheritage.org deployed by terraform. The inventory section is created accordingly[1].
The journal_client is running.
vsellier closed T3175: Prepare production environment, a subtask of T2912: Next generation archive counters, as Resolved.
production: add counters1 node
counters: Declare production node
vsellier requested review of D5338: counters: Declare production node.
vsellier added a revision to T3175: Prepare production environment: D5338: counters: Declare production node.
vagrant: add prod-counters1 vm
vsellier changed the status of T3165: Generate historical data from the new counters series, a subtask of T2912: Next generation archive counters, from Open to Work in Progress.
vsellier changed the status of T3165: Generate historical data from the new counters series from Open to Work in Progress.
vsellier closed T3164: Expose counters in prometheus format, a subtask of T2912: Next generation archive counters, as Resolved.
vsellier committed rSPSITE9558e50ce902: counters: count objects from more topics (authored by vsellier).
counters: count objects from more topics
vsellier added a comment to D5332: counters: count objects from more topics.
:)
thanks
vsellier added a comment to T3164: Expose counters in prometheus format.
The counters are now exposed throught a /metrics enpoint and ingested by prometheus.
They are well tagged per environment so we will be able to isolate the counters for each one:
vsellier requested review of D5332: counters: count objects from more topics.