Fixed in D7487
Feed Advanced Search
Apr 29 2022
Apr 29 2022
Apr 27 2022
Apr 27 2022
seirl added a comment to T3021: Investigate why reading the journal of the content table takes so long.
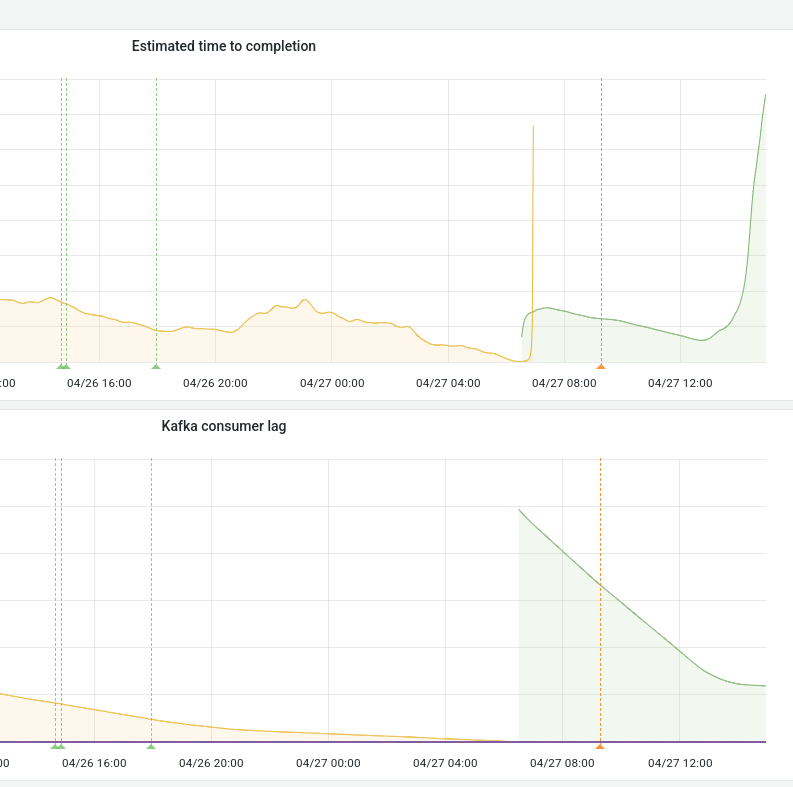
seirl reopened T3021: Investigate why reading the journal of the content table takes so long as "Open".
seirl closed T3021: Investigate why reading the journal of the content table takes so long as Resolved.
No longer happens with a more recent stack
Apr 5 2022
Apr 5 2022
zack changed the status of T1743: create a nice landing web page for exported dataset from Open to Work in Progress.
zack changed the status of T3329: document ORC format dataset availability from Open to Work in Progress.
Mar 30 2022
Mar 30 2022
Mar 22 2022
Mar 22 2022
Jan 25 2022
Jan 25 2022
Jan 24 2022
Jan 24 2022
Jan 4 2022
Jan 4 2022
Jul 29 2021
Jul 29 2021
vlorentz moved T2431: Document how to export the graph edge dataset from sys-admin (docs/sysadm) to developers (docs/devel/) on the Documentation board.
vlorentz added a comment to T2431: Document how to export the graph edge dataset.
It is now somewhat documented here: https://forge.softwareheritage.org/source/swh-environment/browse/master/docker/services/swh-graph/entrypoint.sh
May 18 2021
May 18 2021
zack updated the task description for T3329: document ORC format dataset availability.
Apr 19 2021
Apr 19 2021
olasd closed T2003: Content replayer may try to copy objects before they are available from an objstorage, a subtask of T1914: Keep mirror of contents on S3 up to date, as Resolved.
Apr 17 2021
Apr 17 2021
ardumont added a comment to T3260: publish swh.dataset to pypi.
This should help:
12:08 <+ardumont> fwiw, i don't see swh-dataset in the jenkins ci declaration so that won't get published 12:08 <+ardumont> https://forge.softwareheritage.org/source/swh-jenkins-jobs/browse/master/jobs/swh-packages.yaml 12:10 <+ardumont> (relatedly without ^ that won't show up in jenkins) 12:10 <+ardumont> related docs https://wiki.softwareheritage.org/wiki/Debian_packaging#Setting_up_the_repository_on_Phabricator and https://wiki.softwareheritage.org/wiki/Debian_packaging#Setting_up_the_repository_on_Phabricator
Apr 7 2021
Apr 7 2021
seirl closed T3178: document how to export the graph dataset automatically, a subtask of T1847: fully automate export of the graph dataset, as Invalid.
Duplicate of T2431
seirl added a parent task for T2431: Document how to export the graph edge dataset: T1847: fully automate export of the graph dataset.
Mar 26 2021
Mar 26 2021
zack reopened T1847: fully automate export of the graph dataset, a subtask of T1848: refresh graph dataset export, as Open.
zack reopened T1847: fully automate export of the graph dataset as "Open".
reopening, as ideally we'd like to have run the entire ORC export once to completion before closing
The ORC exporter is done, and it's likely that we won't provide CSV exports in the future, or we'll generate them from the ORC format.
seirl closed T1847: fully automate export of the graph dataset, a subtask of T1848: refresh graph dataset export, as Resolved.
Mar 8 2021
Mar 8 2021
rdicosmo added a parent task for T1848: refresh graph dataset export: T3085: Complete and updated copy of the archive on S3 (objects+graph).
Mar 4 2021
Mar 4 2021
Feb 2 2021
Feb 2 2021
seirl triaged T3021: Investigate why reading the journal of the content table takes so long as Normal priority.
Sep 22 2020
Sep 22 2020
moranegg moved T2431: Document how to export the graph edge dataset from Backlog to archive-users (docs/user-guides/) on the Documentation board.
Sep 17 2020
Sep 17 2020
zack changed the status of T1847: fully automate export of the graph dataset, a subtask of T1848: refresh graph dataset export, from Open to Work in Progress.
zack changed the status of T1847: fully automate export of the graph dataset from Open to Work in Progress.
Sep 16 2020
Sep 16 2020
seirl added a comment to T1847: fully automate export of the graph dataset.
No, only the edge part is done, we still need a parquet and a CSV exporter :/
zack removed a parent task for T1848: refresh graph dataset export: T1868: refresh compressed representation of the archive.
zack added a comment to T1847: fully automate export of the graph dataset.
I think this is (reasonably) done now, please check and close it.
zack added a comment to T1848: refresh graph dataset export.
Sep 4 2020
Sep 4 2020
Jun 3 2020
Jun 3 2020
zack renamed T2431: Document how to export the graph edge dataset from Documentat how to export the graph edge dataset to Document how to export the graph edge dataset.
zack changed the status of T1796: Datasets exported from Spark are missing some rows from Resolved to Wontfix.
We no longer export edges from Spark
seirl closed T1741: graph dataset: update to use persistent identifiers everywhere, a subtask of T1848: refresh graph dataset export, as Resolved.
We no longer export edges per file type.
Apr 15 2020
Apr 15 2020
seirl added a comment to T2361: WARNING:swh.core.cli:Could not load subcommand dataset: No module named 'swh.dataset.cli'.
Temporary fix here until the branch that implements this entrypoint is merged: https://forge.softwareheritage.org/rDDATASETbe9e71ba1f858bbb8f44649306b919a1fa965ea2
zack triaged T2361: WARNING:swh.core.cli:Could not load subcommand dataset: No module named 'swh.dataset.cli' as Normal priority.
Jan 23 2020
Jan 23 2020
olasd added a comment to T1914: Keep mirror of contents on S3 up to date.
We've now hit T2003 hard as the client caught up with the head of the local kafka cluster. That's why the curve is flattening out currently, as I stopped the replayers until the queue is implemented.
Dec 7 2019
Dec 7 2019
olasd added a comment to T1914: Keep mirror of contents on S3 up to date.
We'll need to address T2003 before this can be closed (if we go the journal client route), so marking accordingly.
olasd renamed T1914: Keep mirror of contents on S3 up to date from synchronously write content objects to AWS during ingestion to Keep mirror of contents on S3 up to date.
olasd added a comment to T1914: Keep mirror of contents on S3 up to date.
I don't think we're going to do this but rather use the journal client approach. (Even more so considering that writing to S3 takes 500ms for each object, which sounds like a silly artificial limit to put on a synchronous process).
Nov 18 2019
Nov 18 2019
zack added a project to T1847: fully automate export of the graph dataset: Compressed graph service.
Aug 19 2019
Aug 19 2019
Jul 14 2019
Jul 14 2019
zack renamed T1914: Keep mirror of contents on S3 up to date from synchronously write content objects to AWS to synchronously write content objects to AWS during ingestion.
Jul 9 2019
Jul 9 2019
Jun 30 2019
Jun 30 2019
zack added a parent task for T1848: refresh graph dataset export: T1868: refresh compressed representation of the archive.
Jun 23 2019
Jun 23 2019
zack added a parent task for T1741: graph dataset: update to use persistent identifiers everywhere: T1848: refresh graph dataset export.
zack added a parent task for T1847: fully automate export of the graph dataset: T1848: refresh graph dataset export.
zack added a subtask for T1848: refresh graph dataset export: T1847: fully automate export of the graph dataset.
Jun 11 2019
Jun 11 2019
Jun 5 2019
Jun 5 2019
Jun 4 2019
Jun 4 2019
May 23 2019
May 23 2019
zack added a project to T1741: graph dataset: update to use persistent identifiers everywhere: Datasets.
zack added a comment to T1743: create a nice landing web page for exported dataset.
A nice related work here are the LAW datasets.