Closed by d355d8973205
Feed Advanced Search
Jun 11 2019
Jun 11 2019
kalpitk updated the summary of D1568: Add End to end tests: Code Highlighting.
Jun 8 2019
Jun 8 2019
anlambert added a project to T1768: Add end to end tests for the frontend part of swh-web: GSoC 2019.
Jun 7 2019
Jun 7 2019
anlambert closed T1786: Improve popovers display on small screens, a subtask of T1477: Improve swh-web design for mobile browsing , as Resolved.
Jun 5 2019
Jun 5 2019
anlambert renamed T1770: Add end to end tests from Add end to end tests using Selenium to Add end to end tests .
anlambert updated the task description for T1786: Improve popovers display on small screens.
Jun 4 2019
Jun 4 2019
hboutemy added a comment to T1724: Maven Central repository support.
I think there's value in making the Maven lister support more Maven repositories than just Maven Central, even if we focus on Maven Central as the first proof of concept.
makes sense. IMHO, it's good to have one issue per repository, since every repository will have its specific topics
Jun 3 2019
Jun 3 2019
olasd added a comment to T1724: Maven Central repository support.
Thanks a lot to @hboutemy for your valuable insights on sources in the Maven central repository, and for the pointer to Reproducible Builds on the JVM.
Jun 2 2019
Jun 2 2019
hboutemy added a comment to T1724: Maven Central repository support.
if you search for source-release or src, yes, you'll find archivable sources
the only issue is that you'll not find many content...
nahimilega added a comment to T1724: Maven Central repository support.
I renamed the issue title to "Maven Central repository Lister" if the intent is to focus on this repository https://maven.apache.org/repository/index.html
hboutemy added a comment to T1724: Maven Central repository support.
I renamed the issue title to "Maven Central repository Lister" if the intent is to focus on this repository https://maven.apache.org/repository/index.html
hboutemy renamed T1724: Maven Central repository support from Maven Lister to Maven Central repository Lister.
May 31 2019
May 31 2019
nahimilega added a comment to T1724: Maven Central repository support.
Creating Your Own Mirror
The size of the central repository is increasing steadily To save us bandwidth and you time, mirroring the entire central repository is >not allowed. (Doing so will get you automatically banned) Instead, we suggest you setup a repository manager as a proxy.
nahimilega added a comment to T1724: Maven Central repository support.
It is not recommended that you scrape or rsync:// a full copy of central as there is a large amount of data there and doing so will get you banned. You can use a program such as those described on the Repository Management page to run your internal repository's server, download from the internet as required, and then hold the artifacts in your internal repository for faster downloading later.
kalpitk claimed T1770: Add end to end tests .
First of all, I think, we need to run the docker (with overridden swh-web) manually. And then run the selenium test cases. (I couldn't find a better approach). However, Jenkins may be configured to run these tests after running the docker-compose.
May 28 2019
May 28 2019
May 27 2019
May 27 2019
nahimilega updated subscribers of T1718: Implement a NuGet(.NET) lister.
May 24 2019
May 24 2019
nahimilega added a comment to T1724: Maven Central repository support.
Extending on what I wrote in the previous comment, I did a bit more research about this.
May 23 2019
May 23 2019
nahimilega added a comment to T1724: Maven Central repository support.
As recommended by @olasd I checkout out Maven Central index ( https://repo.maven.apache.org/maven2/.index/) this is a
May 22 2019
May 22 2019
nahimilega updated the task description for T1724: Maven Central repository support.
nahimilega updated subscribers of T1724: Maven Central repository support.
Comment by @olasd
nahimilega renamed T1724: Maven Central repository support from Maven Central (JAVA) lister to Maven Lister.
May 21 2019
May 21 2019
anlambert added a comment to T1477: Improve swh-web design for mobile browsing .
@kalpitk , that's a great start.
I propose changes to the following to improve the mobile website -
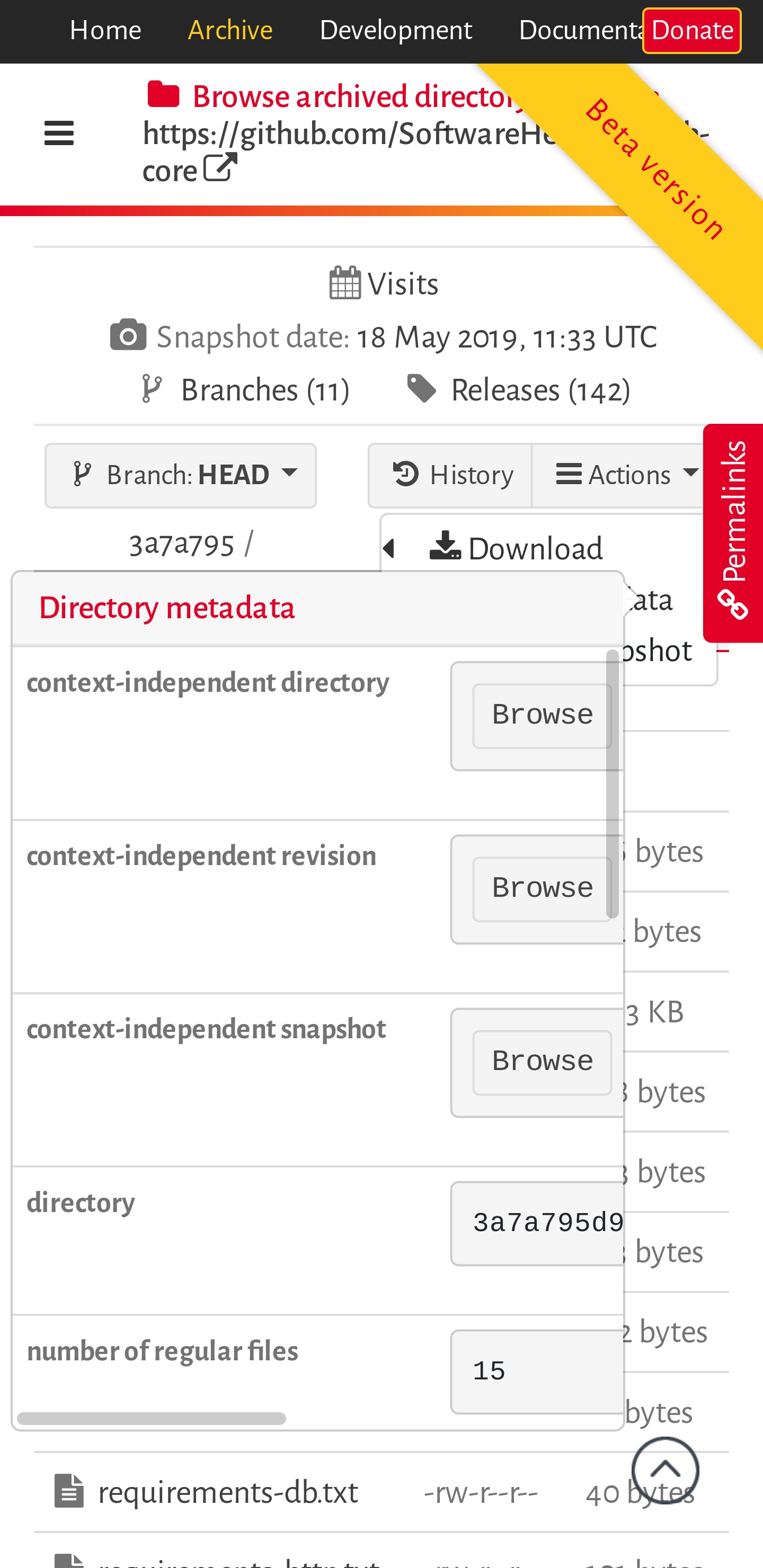
In the directory view, 'Mode' can be removed for mobile website. It would look cleaner.In the mobile view, 'Beta version' obstructs the view. I think it would be better to hide this too.The menu in browse, doesn't look nice. I think this would require some rework.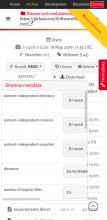
'Donate' button overlaps on most of devices. For mobile devices, either remove the button or maybe remove class swh-position-right.hide 'go to top' button when already on top (for desktop view also)DataTable headers don't scroll currently in mobile view. Either make the headers scroll too or make it mobile responsive (it will appear in form of dropdown in mobile view)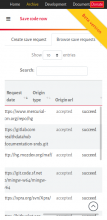
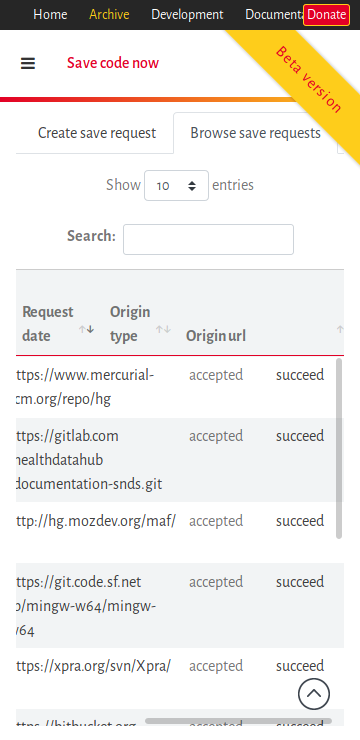
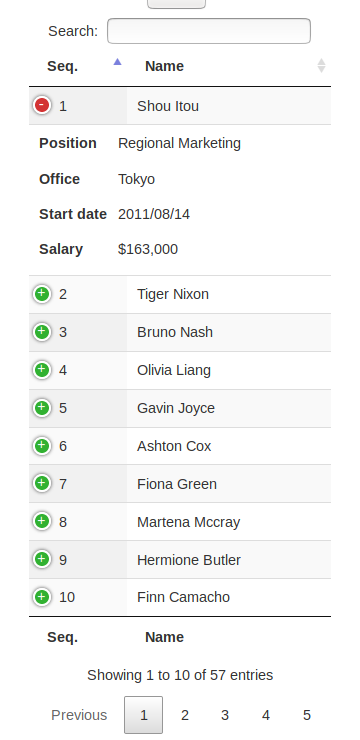
May 20 2019
May 20 2019
May 17 2019
May 17 2019
May 16 2019
May 16 2019
nahimilega added a comment to T1718: Implement a NuGet(.NET) lister.
@olasd recommended trying the listing approach for NuGET lister we discussed(to fetch for repository key in the api response), As recommended, I tried the approach on small dataset. I tried it on 1412 repositories are all of them were quite latest. I found 0 repository URL in them and in 900 of them repository key was empty(ie they were blank string). I think we need to change our approach.
nahimilega updated subscribers of T1718: Implement a NuGet(.NET) lister.
nahimilega added a comment to T1718: Implement a NuGet(.NET) lister.
As discussed on IRC the source code link for the repository is in very few of the repositories and the version control system used by repositories is not mentioned in the API response.
One way is Repository URL and the repository type field are present in .nuspec file for each project, so we have to download that file for each project and get source URL but the problem with this is downloading all binary packages to get a small chance to find a link to a source repository sounds like a lot of work, bandwidth and computing power for not much gain and that would only cover one of the ways package maintainers can set the source code information; the aforementioned blog post listed at least four
May 15 2019
May 15 2019
eddelbuettel added a comment to T1709: implement an R-cran lister.
Yes, for history I do not believe we have an easy answer for SWH (and the world at large) to consume. We may have approximations; I'll check with Gabor and others.
zack added a comment to T1709: implement an R-cran lister.
@eddelbuettel yeah, if there isn't a standard way to go all the way back in time, it's OK to currently only ingest what's currently returned as available. In the medium/long term it will converge to having archived everything (w.r.t. the considered time frame) anyway. And we can always retrofit later on stuff that is archived elsewhere. But I wouldn't want to make this a blocker to start archiving what's (easily) listable now.
eddelbuettel added a comment to T1709: implement an R-cran lister.
Nicholas: Sadly, one can't. I kinda/sorta have that implicitly as I have been running CRANberries since 2007 or so.
olasd added a comment to T1709: implement an R-cran lister.
Expanding on what Dirk Eddelbuettel posted on IRC when we talked about that, a minimal R script to fetch the current package information would be:
faux added a comment to T1709: implement an R-cran lister.
@nahimilega it is probably a two line script. install R and do readRDS() and you will get a data.frame object which is just like a table and has columns and then you can extract what you want. Cheers :). BTW when I did readRDS it retrieved a lot of links and I don't know about the lister that much but you can pickup from there.
nahimilega added a comment to T1718: Implement a NuGet(.NET) lister.
API Documentation -
https://docs.microsoft.com/en-us/nuget/api/catalog-resource#base-url
nahimilega added a comment to T1709: implement an R-cran lister.
@olasd I do not have any familiarity with R language. Learning some basics and making this script would take me around a week. I was wondering it is possible that someone in Software Heritage who have some experience with R can write this script as it would be a matter of minutes to the person who knows R.
Is it possible to do so?
olasd added a comment to T1709: implement an R-cran lister.
May 13 2019
May 13 2019
nahimilega added a comment to T1709: implement an R-cran lister.
Here is an implementation plan for making R-CRAN lister.
I have taken inspiration from the pypi lister.
To make lister.py for R-CRAN, we need to inherit SimpleLister class and override ingest_data() function and change its first line (where safely_issue_request() is called) to call the function which would run R script to return a json response.
Then after that it is quite like any normal response, we just need to implement following function list_packages, compute url, get_model_from_repo, task_dict and transport_response_simplified.
zack renamed T1709: implement an R-cran lister from Implementation of R-cran lister to implement an R-cran lister.
nahimilega updated subscribers of T1709: implement an R-cran lister.
@faux on IRC mentioned that there is a public DB dump (https://cran.r-project.org/web/dbs) which might be helpful for the purpose.
This DB dump contains files with .rds extension which is used by R language. Here are a couple of rows from that DB dump https://forge.softwareheritage.org/P396
May 7 2019
May 7 2019
May 6 2019
May 6 2019