The model number to use on the request is : ST6000NM0115
There is an obscure message limiting the number of return / country / year to 3 (!):
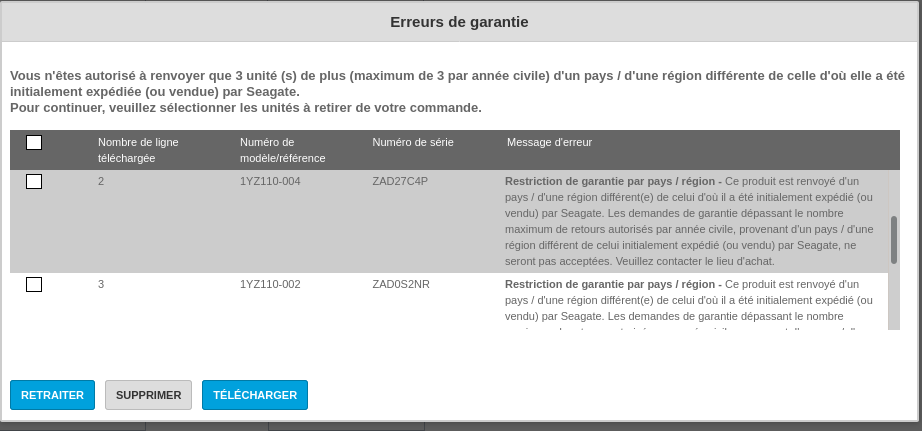
The model number to use on the request is : ST6000NM0115
There is an obscure message limiting the number of return / country / year to 3 (!):
The test of /dev/sdb finally ends ... in error :
SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 80% 26004 2559298584
So we have 2 disks to replace on each server. What's weird is that the 2 disks to replace are at the same position on each server...
the test is still running on one disk on storage1 (sdb). No new errors were discovered on all the other disk
LGTM
LGTM
version v0.4.1 created with the last commit (rDSEA47db624364d4e781f8fa157b2d72d0eb9929b7a0)
LGTM
thanks for the query to fix the index
Tests launched :
root@db1:~# echo /dev/sd{a..n} | xargs -t -n1 smartctl -t long
smartctl -t long /dev/sda
smartctl 6.6 2017-11-05 r4594 [x86_64-linux-5.9.0-0.bpo.2-amd64] (local build)
Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.orgComplete disk statuses :
root@db1:~# ls /dev/sd{a..n} | xargs -t -n1 smartctl -a | grep -e "/dev/sd?" -e Reallocated_Sector_Ct -e "Model Family" -e "Serial Number" -e "Reported_Uncorrect" -e lifetime -e "Extended offline" -e "Offline_Uncorrectable"
smartctl -a /dev/sda
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27CCS
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 8
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdb
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27C4P
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 8
# 1 Extended offline Completed: read failure 70% 25421 4131034152
smartctl -a /dev/sdc
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27DW0
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdd
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27A44
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sde
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27BA5
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdf
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27DCG
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdg
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD270KS
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25431 -
smartctl -a /dev/sdh
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27A4P
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25431 -
smartctl -a /dev/sdi
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD27E48
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25431 -
smartctl -a /dev/sdj
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD26YN2
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdk
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD279XY
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25432 -
smartctl -a /dev/sdl
Model Family: Seagate Enterprise Capacity 3.5 HDD
Serial Number: ZAD279ZX
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
# 1 Extended offline Completed without error 00% 25427 -
smartctl -a /dev/sdm
Model Family: Intel 730 and DC S35x0/3610/3700 Series SSDs
Serial Number: PHDV71810017150MGN
5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
# 1 Extended offline Completed without error 00% 25415 -
smartctl -a /dev/sdn
Model Family: Intel 730 and DC S35x0/3610/3700 Series SSDs
Serial Number: PHDV718004DM150MGN
5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
# 1 Extended offline Completed without error 00% 25415 -Reducing priority to normal as there is no more risks for the data
It depends of what will be implemented in T2936, but a new reindex will probably have to be done to fix the search. It will be the opportunity to think on how doing it without killing all the search
@vlorentz I was checking some differences between swh-search and the current search. does the journal client has to listen the origin_visit topic? It seems that `origin_visit_status should be enough to match the behavior of the search in the webapp.
previous comment moved to T2903#56023
The benchmark is done:
Version 1.98 ------Sequential Output------ --Sequential Input- --Random-
-Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Name:Size etc /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
esnode1-zfs-arc 63G 312k 99 478m 49 200m 43 640k 93 445m 53 400.8 31
Latency 31118us 58579us 748ms 231ms 78052us 275ms
Version 1.98 ------Sequential Create------ --------Random Create--------
esnode1-zfs-arc-lim -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 16384 24 +++++ +++ 16384 7 16384 35 +++++ +++ 16384 6
Latency 145ms 2012us 826ms 105ms 21us 842ms
1.98,1.98,esnode1-zfs-arc-limited,1,1609729287,63G,,8192,5,312,99,489919,49,204649,43,640,93,455669,53,400.8,31,16,,,,,4059,24,+++++,+++,3023,7,11686,35,+++++,+++,2398,6,31118us,58579us,748ms,231ms,78052us,275ms,145ms,2012us,826ms,105ms,21us,842ms(sorry for the formating, didn't find how to make it better)
webapp1 is now plugged on the real live production index
Let monitor the behavior with real searches.
First constatation, the search retrieves all the documents and is not as progressive as the random search script.
The response times are longer than expected:
Jan 06 09:59:46 search1 python3[813]: 2021-01-06 09:59:46 [813] elasticsearch:INFO GET http://search-esnode1.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:3.399s] Jan 06 10:06:18 search1 python3[848]: 2021-01-06 10:06:18 [848] elasticsearch:INFO GET http://search-esnode1.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:7.422s] Jan 06 10:06:21 search1 python3[813]: 2021-01-06 10:06:21 [813] elasticsearch:INFO GET http://search-esnode3.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:5.077s] Jan 06 10:07:32 search1 python3[813]: 2021-01-06 10:07:32 [813] elasticsearch:INFO GET http://search-esnode2.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:4.819s] Jan 06 10:08:06 search1 python3[813]: 2021-01-06 10:08:06 [813] elasticsearch:INFO GET http://search-esnode1.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:2.700s] Jan 06 10:08:15 search1 python3[813]: 2021-01-06 10:08:15 [813] elasticsearch:INFO GET http://search-esnode3.internal.softwareheritage.org:9200/origin/_search?size=100 [status:200 request:2.414s]
the performances looks acceptable as it for a small number of parallel searches (~10), let's try now with real searches, it will also help to adapt the cluster configuration and validate the behavior
The new disk are ok according the smart test:
root@esnode1:~# echo /dev/sd{b,c} | xargs -n1 smartctl -a | grep -A2 "Self-test log"
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 3 -
--
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 3 -The 2 disks were replaced :
root@esnode1:~# smartctl -a /dev/sdb smartctl 6.6 2017-11-05 r4594 [x86_64-linux-5.9.0-0.bpo.2-amd64] (local build) Copyright (C) 2002-17, Bruce Allen, Christian Franke, www.smartmontools.org
Can this task be closed since the subject was addressed in T2620 ?
In the new configuration, after a few time without search, the first ones are taking some time before stabilizing to the old values :
❯ ./random_search.sh 12:36:37
the index configuration was reset to its default :
cat >/tmp/config.json <<EOF
{
"index" : {
"translog.sync_interval" : null,
"translog.durability": null,
"refresh_interval": null
}
}
EOF❯ curl -s http://192.168.100.81:9200/origin/_settings\?pretty
{
"origin" : {
"settings" : {
"index" : {
"refresh_interval" : "60s",
"number_of_shards" : "90",
"translog" : {
"sync_interval" : "60s",
"durability" : "async"
},
"provided_name" : "origin",
"creation_date" : "1608761881782",
"number_of_replicas" : "1",
"uuid" : "Mq8dnlpuRXO4yYoC6CTuQw",
"version" : {
"created" : "7090399"
}
}
}
}
}
❯ curl -s -H "Content-Type: application/json" -XPUT http://192.168.100.81:9200/origin/_settings\?pretty -d @/tmp/config.json
{
"acknowledged" : true
}
❯ curl -s http://192.168.100.81:9200/origin/_settings\?pretty
{
"origin" : {
"settings" : {
"index" : {
"creation_date" : "1608761881782",
"number_of_shards" : "90",
"number_of_replicas" : "1",
"uuid" : "Mq8dnlpuRXO4yYoC6CTuQw",
"version" : {
"created" : "7090399"
},
"provided_name" : "origin"
}
}
}
}A *simple* search doesn't looked impacted (it's not a real benchmark):
❯ ./random_search.sh
Closing this task as all the direct work is done.
The documentation will be addressed in T2920
The backfill was done in a couple of days.
search1.internal.softwareheritage.org vm deployed.
The configuration of the index was automatically performed by puppet during the initial provisionning.
Index template created in elasticsearch with 1 replica and 90 shards to have the same number of shards on each node:
export ES_SERVER=192.168.100.81:9200
curl -XPUT -H "Content-Type: application/json" http://$ES_SERVER/_index_template/origin\?pretty -d '{"index_patterns": "origin", "template": {"settings": { "index": { "number_of_replicas":1, "number_of_shards": 90 } } } } 'search-esnode[1-3] installed with zfs configured :
apt update && apt install linux-image-amd64 linux-headers-amd64 # reboot to upgrade the kernel apt install libnvpair1linux libuutil1linux libzfs2linux libzpool2linux zfs-dkms zfsutils-linux zfs-zed systemctl stop elasticsearch rm -rf /srv/elasticsearch/nodes/0 zpool create -O atime=off -m /srv/elasticsearch/nodes elasticsearch-data /dev/vdb chown elasticsearch: /srv/elasticsearch/nodes
Inventory was updated to reserve the elastisearch vms :
The webapp is available at https://webapp1.internal.softwareheritage.org
In prevision of the deployment, the production index present on the staging's elasticsearch was renamed from origin-production2 to production_origin (a clone operation will be user [1], the original index will be let in place)
[1] https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-clone-index.html
Remove useless fixture declaration
thanks, I change that
Use a prefix instead of changing the index name.
Make it optional to avoid to have to rename the index on the instances already deployed
the shards reallocation is still in progress :
~ ❯ curl -s http://esnode3.internal.softwareheritage.org:9200/_cat/shards\?h\=prirep,node | sort | uniq -c 09:40:21
1216 p esnode1
1183 p esnode2
1 p esnode2 -> 192.168.100.61 t4iSb7f1RZmEwpH4O_OoGw esnode1
1840 p esnode3
1 p esnode3 -> 192.168.100.61 t4iSb7f1RZmEwpH4O_OoGw esnode1
1208 r esnode1
1845 r esnode2
1188 r esnode3p: primary shard
r: replica shard
The atime was activated by default. I switched to relatime :
root@esnode1:~# zfs get all | grep time elasticsearch-data atime on default elasticsearch-data relatime off default
~ ❯ curl -s http://esnode3.internal.softwareheritage.org:9200/_cat/nodes\?v; echo; curl -s http://esnode3.internal.softwareheritage.org:9200/_cat/health\?v 16:02:37 ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 192.168.100.61 3 57 0 0.35 0.25 0.12 dilmrt - esnode1 192.168.100.63 35 97 1 0.68 0.65 0.70 dilmrt * esnode3 192.168.100.62 35 96 2 0.66 0.75 0.82 dilmrt - esnode2
As puppet can be restart to avoid elasticsearch to restart before zfs is configured, zfs was manually installed :
root@esnode1:~# sfdisk -l /dev/sda Disk /dev/sda: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors Disk model: HGST HUS726020AL Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: gpt Disk identifier: 543964DA-9ECA-4222-952D-BA8A90FAB2B9
root@esnode1:~# umount /srv/elasticsearch root@esnode1:~# diff -U3 /tmp/fstab /etc/fstab --- /tmp/fstab 2020-12-22 11:37:17.318967701 +0000 +++ /etc/fstab 2020-12-22 11:37:28.687049499 +0000 @@ -11,5 +11,3 @@ UUID=AE23-D5B8 /boot/efi vfat umask=0077 0 1 # swap was on /dev/sda3 during installation UUID=3eaaa22d-e1d2-4dde-9a45-d2fa22696cdf none swap sw 0 0 -UUID=6adb1e63-e709-4efb-8be1-76818b1b4751 /srv/kafka ext4 errors=remount-ro 0 0 -/dev/md127 /srv/elasticsearch xfs defaults,noatime 0 0
The fix is deployed in staging and production
The disks can't be replaced before beginning of January because of a closed logistic service
Dell was notified about the delay for the disk replacement. The next package retrieval attempt by UPS is scheduled for the *2020-01-11*
testing in staging with a manual change in the code to force an assertion, It works well
Everything looks good, let's try to add some documentation before closing the issue
Tested locally, it looks good. I just add a small comment about the installation directory usually in /opt instead of the user home dir.