Remove the tests because the flask application is not reinitialized
between 2 unit tests and testing the ElasticSearch class instanciation
with different configuration by flask is not working.
Feed Advanced Search
Mar 4 2021
Mar 4 2021
vsellier updated the diff for D5196: Allow to instantiate the service with default indexes configuration.
vsellier added a comment to T3081: ZFS failures detected on belvedere.
The 4 files seems to be accessible without errors which look like a good news ;):
root@belvedere:~# time cp /srv/softwareheritage/postgres/11/indexer/base/16406/774467031.317 /dev/null
vsellier changed the status of T3083: Deploy swh-search v0.7.0/v0.7.1 from Open to Work in Progress.
vsellier added a comment to T3054: Scale out object storage design.
I have found some interesting pointers relative to the management of small files in hdfs (found them when looking for unrelated other stuff). Is it something you have identified and excluded from the scope due to some blockers ?
vsellier added a comment to T3081: ZFS failures detected on belvedere.
vsellier added a comment to T3081: ZFS failures detected on belvedere.
Isn't this around when we've restarted production after expanding the storage pool?
The loaders were restarted in late November, but perhaps more of them were launched at this moment
vsellier updated the task description for T3081: ZFS failures detected on belvedere.
Mar 3 2021
Mar 3 2021
vsellier committed rDSEA9e0db2bd4fd0: Ensure the elasticsearch indexes are initialized before the first request (authored by vsellier).
Ensure the elasticsearch indexes are initialized before the first request
vsellier closed T3033: Replace first disk on storage1.staging, a subtask of T2939: Replace out of order disks on db1.staging and storage1.staging, as Resolved.
vsellier added a comment to T3033: Replace first disk on storage1.staging.
The disk was tested completely with read/write operations (interrupted on the 2d pass)
vsellier updated the summary of D5193: Ensure the elasticsearch indexes are initialized before the first request.
vsellier updated the diff for D5193: Ensure the elasticsearch indexes are initialized before the first request.
- fix wrong error log level
- fix typo on the commit message
vsellier requested review of D5193: Ensure the elasticsearch indexes are initialized before the first request.
vsellier committed rDSEA7c795a603f7a: Use elasticsearch aliases to simplify maintenance operations (authored by vsellier).
Use elasticsearch aliases to simplify maintenance operations
vsellier added a comment to T3081: ZFS failures detected on belvedere.
For the record, it seems the 4 impacted files are related to the primary key of the softwareheritage-indexer.content_mimetype table
vsellier added a comment to P966 Snapshot branches queries performances.
yep it's weird, but after looking at the code of the function, I realized it seems to be a known problem :
https://forge.softwareheritage.org/source/swh-storage/browse/master/swh/storage/sql/40-funcs.sql$665-667
vsellier added a comment to P966 Snapshot branches queries performances.
limit 2:
https://explain.depesz.com/s/UW9Z
softwareheritage=> explain analyze with filtered_snapshot_branches as (
select '\xdfea9cb3249b932235b1cd60ed49c5e316a03147'::bytea as snapshot_id, name, target, target_type
from snapshot_branches
inner join snapshot_branch on snapshot_branches.branch_id = snapshot_branch.object_id
where snapshot_id = (select object_id from snapshot where snapshot.id = '\xdfea9cb3249b932235b1cd60ed49c5e316a03147'::bytea)
and (NULL :: snapshot_target[] is null or target_type = any(NULL :: snapshot_target[]))
)
select snapshot_id, name, target, target_type
from filtered_snapshot_branches
where name >= '\x'::bytea
and (NULL is null or convert_from(name, 'utf-8') ilike NULL)
and (NULL is null or convert_from(name, 'utf-8') not ilike NULL)
order by name limit 2;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1004.01..6764.11 rows=2 width=76) (actual time=172523.081..173555.673 rows=2 loops=1)
InitPlan 1 (returns $0)
-> Index Scan using snapshot_id_idx on snapshot (cost=0.57..2.59 rows=1 width=8) (actual time=0.028..0.036 rows=1 loops=1)
Index Cond: ((id)::bytea = '\xdfea9cb3249b932235b1cd60ed49c5e316a03147'::bytea)
-> Gather Merge (cost=1001.43..168852423.27 rows=58628 width=76) (actual time=172523.079..173555.661 rows=2 loops=1)
Workers Planned: 2
Params Evaluated: $0
Workers Launched: 2
-> Nested Loop (cost=1.40..168844656.12 rows=24428 width=76) (actual time=126442.320..167761.276 rows=2 loops=3)
-> Parallel Index Scan using snapshot_branch_name_target_target_type_idx on snapshot_branch (cost=0.70..12612971.47 rows=154824599 width=52) (actual time=0.077..80926.811 rows=23123612 loops=3)
Index Cond: (name >= '\x'::bytea)
-> Index Only Scan using snapshot_branches_pkey on snapshot_branches (cost=0.70..1.01 rows=1 width=8) (actual time=0.004..0.004 rows=0 loops=69370837)
Index Cond: ((snapshot_id = $0) AND (branch_id = snapshot_branch.object_id))
Heap Fetches: 5
Planning Time: 0.993 ms
Execution Time: 173555.864 ms
(16 rows)vsellier added a comment to P966 Snapshot branches queries performances.
It seems there are some differences in term of indexes between the main and replica databases.
On the replica, only the primary keys are present on the snapshot_branches and the snapshot_branch tables. Perhaps the query optimizer is confused by something and is doing a wrong choice somewhere.
vsellier updated subscribers of T3081: ZFS failures detected on belvedere.
No problems are detected on the IDrac, smartcl on the drives looks ok.
vsellier closed T3061: swh-search: Deploy visit_types indexation in production, a subtask of T2869: web search: allow to filter by origin type, as Resolved.
The lag has recovered so the index should contains the visit_type for all origin now
vsellier added a comment to T3081: ZFS failures detected on belvedere.
(not related or directly retated to the issue) Looking at some potential issues on disk i/os,I discovered a weird behavior change on the i/o on belvedere after the 2020-12-31 :
vsellier added a comment to T3081: ZFS failures detected on belvedere.
There is no errors on the postgresql logs related to the files listed on the zfs status but I'm not sure the indexer database is read.
vsellier added a comment to T3081: ZFS failures detected on belvedere.
It seems there are some reccurring alerts on the system journal about several disks since some time :
Feb 24 01:33:36 belvedere.internal.softwareheritage.org kernel: sd 0:0:14:0: [sdi] tag#808 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:36 belvedere.internal.softwareheritage.org kernel: sd 0:0:14:0: [sdi] tag#808 Add. Sense: Defect list not found Feb 24 01:33:39 belvedere.internal.softwareheritage.org kernel: sd 0:0:16:0: [sdk] tag#650 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:39 belvedere.internal.softwareheritage.org kernel: sd 0:0:16:0: [sdk] tag#650 Add. Sense: Defect list not found Feb 24 01:33:41 belvedere.internal.softwareheritage.org kernel: sd 0:0:17:0: [sdl] tag#669 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:41 belvedere.internal.softwareheritage.org kernel: sd 0:0:17:0: [sdl] tag#669 Add. Sense: Defect list not found Feb 24 01:33:43 belvedere.internal.softwareheritage.org kernel: sd 0:0:18:0: [sdm] tag#682 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:43 belvedere.internal.softwareheritage.org kernel: sd 0:0:18:0: [sdm] tag#682 Add. Sense: Defect list not found Feb 24 01:33:44 belvedere.internal.softwareheritage.org kernel: sd 0:0:21:0: [sdo] tag#668 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:44 belvedere.internal.softwareheritage.org kernel: sd 0:0:21:0: [sdo] tag#668 Add. Sense: Defect list not found Feb 24 01:33:44 belvedere.internal.softwareheritage.org kernel: sd 0:0:22:0: [sdp] tag#682 Sense Key : Recovered Error [current] [descriptor] Feb 24 01:33:44 belvedere.internal.softwareheritage.org kernel: sd 0:0:22:0: [sdp] tag#682 Add. Sense: Defect list not found ...
root@belvedere:/var/log# journalctl -k --since=yesterday | awk '{print $8}' | sort | uniq -c
274 [sdi]
274 [sdk]
274 [sdl]
274 [sdm]
274 [sdo]
274 [sdp]vsellier updated the task description for T3081: ZFS failures detected on belvedere.
vsellier renamed T3081: ZFS failures detected on belvedere from ZFS failure detected on belvedere to ZFS failures detected on belvedere.
vsellier changed the status of T3081: ZFS failures detected on belvedere from Open to Work in Progress.
vsellier updated the diff for D5179: Use elasticsearch aliases to simplify maintenance operations.
Configure the indexes with a Dict with an entry per index type
Mar 2 2021
Mar 2 2021
lgtm
Add missing server tests
vsellier added inline comments to D5179: Use elasticsearch aliases to simplify maintenance operations.
vsellier updated the diff for D5184: Add missing server tests.
Remove a useless parameter of the load_and_check_config function
vsellier retitled D5184: Add missing server tests from Add server tests to Add missing server tests.
vsellier updated the diff for D5184: Add missing server tests.
Update according review's feedbacks
vsellier added a comment to D5179: Use elasticsearch aliases to simplify maintenance operations.
What does that mean? Can an alias reference multiple indexes? How does that work in terms of ids for example?
yes, an alias can reference multi indexes. If same ids are present in several indexes, the risk is to have duplicate result if the documents are matching the search.
vsellier requested review of D5184: Add missing server tests.
vsellier added a comment to T3033: Replace first disk on storage1.staging.
To be sure the disk is ok as it seems there is a high count of Raw_Read_Error_Rate, a complete read/write test was launched. It seems it will take some times to complete:
root@storage1:~# badblocks -v -w -B -s -b 4096 /dev/sda Checking for bad blocks in read-write mode From block 0 to 1465130645 Testing with pattern 0xaa: 0.74% done, 3:16 elapsed. (0/0/0 errors)
vsellier added a comment to T3033: Replace first disk on storage1.staging.
The disk was put back in place on the server.
vsellier added a comment to D5179: Use elasticsearch aliases to simplify maintenance operations.
Will we used different indexes for T2073 ?
Even with several indexes, It's not clear (for me at least) if using a unique read alias with several underlying indexes could be more advantageous. It will probably depend of how the search will be used from the api perspective.
Perhaps it should be more prudent to keep this diff as simple as possible and implement the eventual improvements in T2073.
WDYT?
vsellier updated the summary of D5179: Use elasticsearch aliases to simplify maintenance operations.
vsellier updated the diff for D5179: Use elasticsearch aliases to simplify maintenance operations.
Update commit message
vsellier requested review of D5179: Use elasticsearch aliases to simplify maintenance operations.
Mar 1 2021
Mar 1 2021
vsellier changed the status of T3076: [swh-search] Improve the index/mapping migration process, a subtask of T2590: Finish the indexer -> swh-search pipeline, from Open to Work in Progress.
vsellier changed the status of T3076: [swh-search] Improve the index/mapping migration process from Open to Work in Progress.
vsellier updated the task description for T3076: [swh-search] Improve the index/mapping migration process.
vsellier renamed T3076: [swh-search] Improve the index/mapping migration process from [swh-search] Improve the migration process to [swh-search] Improve the index/mapping migration process.
vsellier renamed T3076: [swh-search] Improve the index/mapping migration process from [use index aliases] to [swh-search] Improve the migration process.
vsellier triaged T3076: [swh-search] Improve the index/mapping migration process as Normal priority.
vsellier closed T3060: Deploy swh-search v0.6.0 in **staging**, a subtask of T2590: Finish the indexer -> swh-search pipeline, as Resolved.
vsellier closed T3060: Deploy swh-search v0.6.0 in **staging**, a subtask of T3058: Metadata search is failing with "failed to parse date field", as Resolved.
the backfill is done, the search on metadata seems to work correctly.
vsellier added a comment to T3033: Replace first disk on storage1.staging.
Good news, the disk was sent during the last week
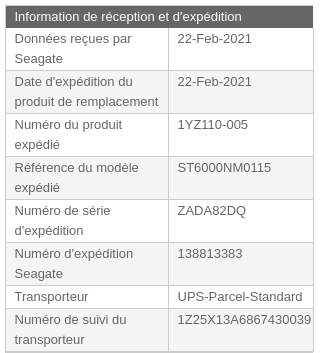
vsellier added a comment to T3067: elasticsearch cluster disk usage and maintenance.
The backfill / reindexation looks aggressive for the cluster and the search. There is a lot of timeouts on the webapp's search
File "/usr/lib/python3/dist-packages/elasticsearch/connection/http_urllib3.py", line 249, in perform_request
raise ConnectionTimeout("TIMEOUT", str(e), e)
elasticsearch.exceptions.ConnectionTimeout: ConnectionTimeout caused by - ReadTimeoutError(HTTPConnectionPool(host='search-esnode3.internal.softwareheritage.org', port=9200): Read timed out. (read timeout=10))Feb 19 2021
Feb 19 2021
vsellier renamed T3063: Servers using the public swh network gateway can't reach inria's ntp servers from Servers behind the firewall can't reach the sesi ntp servers to Servers using the public swh network gateway can't reach inria's ntp servers.
vsellier added a comment to T3063: Servers using the public swh network gateway can't reach inria's ntp servers.
it seems the filtering is a good culprit as from a production worker, directly plugged on the public swh vlan, the inria's ntp server can't be reach either :
vsellier@worker01 ~ % ip route default via 128.93.166.62 dev ens18 onlink 128.93.166.0/26 dev ens18 proto kernel scope link src 128.93.166.16 192.168.100.0/24 dev ens19 proto kernel scope link src 192.168.100.21 192.168.101.0/24 via 192.168.100.1 dev ens19 192.168.200.0/21 via 192.168.100.1 dev ens19 vsellier@worker01 ~ % sudo systemctl stop ntp vsellier@worker01 ~ % sudo ntpdate sesi-ntp1.inria.fr 19 Feb 17:30:54 ntpdate[1868740]: no server suitable for synchronization found vsellier@worker01 ~ % sudo ntpdate europe.pool.ntp.org 19 Feb 17:31:42 ntpdate[1868761]: step time server 185.125.206.73 offset -0.555238 sec vsellier@worker01 ~ % sudo systemctl start ntp
vsellier triaged T3063: Servers using the public swh network gateway can't reach inria's ntp servers as High priority.
vsellier added a comment to T3033: Replace first disk on storage1.staging.
There is still no changes on the ticket status page the 2021-02-19:
vsellier triaged T3062: deposit: loader instanciation is failing with an error "unexpected keyword argument 'extraction_dir'" as Unbreak Now! priority.
vsellier added a comment to T3061: swh-search: Deploy visit_types indexation in production.
- journal-client and swh-search service stopped
- package upgraded
root@search1:/etc/systemd/system# apt list --upgradable Listing... Done python3-swh.search/unknown 0.6.1-1~swh1~bpo10+1 all [upgradable from: 0.5.0-1~swh1~bpo10+1] python3-swh.storage/unknown 0.23.2-1~swh1~bpo10+1 all [upgradable from: 0.23.1-1~swh1~bpo10+1] root@search1:/etc/systemd/system# apt dist-upgrade
- new mapping applyed and checked :
- before
% curl -s http://${ES_SERVER}/origin/_mapping\?pretty | jq '.origin.mappings' > mapping-v0.5.0.json- upgrade
swhstorage@search1:~$ /usr/bin/swh search --config-file /etc/softwareheritage/search/server.yml initialize INFO:elasticsearch:HEAD http://search-esnode1.internal.softwareheritage.org:9200/origin [status:200 request:0.036s] INFO:elasticsearch:PUT http://search-esnode2.internal.softwareheritage.org:9200/origin/_mapping [status:200 request:0.196s] Done.
- after
% curl -s http://${ES_SERVER}/origin/_mapping\?pretty | jq '.origin.mappings' > mapping-v0.6.1.json- check
% diff -U3 mapping-v0.5.0.json mapping-v0.6.1.json --- mapping-v0.5.0.json 2021-02-19 15:10:23.336628008 +0000 +++ mapping-v0.6.1.json 2021-02-19 15:12:50.660635267 +0000 @@ -1,4 +1,5 @@ { + "date_detection": false, "properties": { "has_visits": { "type": "boolean" @@ -25,6 +26,9 @@ } }, "analyzer": "simple" + }, + "visit_types": { + "type": "keyword" } } }
- reset the offsets
% /opt/kafka/bin/kafka-consumer-groups.sh --bootstrap-server $SERVER --reset-offsets --topic swh.journal.objects.origin_visit --to-earliest --group swh.search.journal_client --execute
vsellier added a comment to T3061: swh-search: Deploy visit_types indexation in production.
- A reindex of the origin index to a backup is in progress to evaluate the possible duration of such operation with production volume
- For this migration, we are lucky as the changes are only new fields declarations. The metadata are not yet ingested in production so the documents don't have to be converted
vsellier moved T3061: swh-search: Deploy visit_types indexation in production from Backlog to in-progress on the System administration board.
vsellier changed the status of T3061: swh-search: Deploy visit_types indexation in production from Open to Work in Progress.
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
- stop the journal client
root@search0:~# systemctl stop swh-search-journal-client@objects.service root@search0:~# puppet agent --disable "stop search journal client to reset offsets"
- reset the offset for the swh.journal.objects.origin_visit topic:
vsellier@journal0 ~ % /opt/kafka/bin/kafka-consumer-groups.sh --bootstrap-server $SERVER --reset-offsets --topic swh.journal.objects.origin_visit --to-earliest --group swh.search.journal_client --execute
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
Regarding the missing visit_type, one of the topic with the visit_type needs to be visited again to populate the fields for all the origins.
As the index was restored from the backup, the fields was only set for the visits done since the last 15days.
The offset will be reset for the origin_visit to limit the work.
vsellier changed the status of T3043: journalbeat:/filebeat Add an environment field on the logs from Open to Work in Progress.
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
Regarding the index size, it seems it's due to a huge number of deleted documents (probably due to the backlog and an update of the documents at each change)
% curl -s http://${ES_SERVER}/_cat/indices\?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open origin HthJj42xT5uO7w3Aoxzppw 80 0 868634 8577610 10.5gb 10.5gb
green close origin-backup-20210209-1736 P1CKjXW0QiWM5zlzX46-fg 80 0
green open origin-v0.5.0 SGplSaqPR_O9cPYU4ZsmdQ 80 0 868121 0 987.7mb 987.7mb
green open origin-toremove PL7WEs3FTJSQy4dgGIwpeQ 80 0 868610 0 987.5mb 987.5mb <-- A clean copy of the origin index has almose the same size as yesterdayForcing a merge seems restore a decent size :
% curl -XPOST -H "Content-Type: application/json" http://${ES_SERVER}/origin/_forcemerge
{"_shards":{"total":80,"successful":80,"failed":0}}%% curl -s http://${ES_SERVER}/_cat/indices\?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open origin HthJj42xT5uO7w3Aoxzppw 80 0 868684 3454 1gb 1gb
green close origin-backup-20210209-1736 P1CKjXW0QiWM5zlzX46-fg 80 0
green open origin-v0.5.0 SGplSaqPR_O9cPYU4ZsmdQ 80 0 868121 0 987.7mb 987.7mb
green open origin-toremove PL7WEs3FTJSQy4dgGIwpeQ 80 0 868610 0 987.5mb 987.5mbIt will be probably something to schedule regularly on production index if size matters
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
The journal clients recovered, so the index is up-to-date.
Let's check some point before closing :
- The index size looks huge (~10g) compared to before the deployment
- it seems some document have no origin_visit_type populated as they should :
swh=> select * from origin where url='deb://Debian/packages/node-response-time'; id | url -------+------------------------------------------ 15552 | deb://Debian/packages/node-response-time (1 row)
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
Feb 18 2021
Feb 18 2021
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
- Copy the backup of the index done in T2780
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
- delete current index
vsellier added a comment to P955 swh-search journal-client offsets before T3060 .
indexed:
"swh.journal.indexed.origin_intrinsic_metadata",0,15044088
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
vsellier added a comment to T3060: Deploy swh-search v0.6.0 in **staging**.
stop the journal clients and swh-search
root@search0:~# puppet agent --disable "swh-search upgrade" root@search0:~# systemctl stop swh-search-journal-client@objects.service root@search0:~# systemctl stop swh-search-journal-client@indexed.service root@search0:~# systemctl stop gunicorn-swh-search.service
update the packages
root@search0:~# apt update && apt list --upgradable ... python3-swh.search/unknown 0.6.0-1~swh1~bpo10+1 all [upgradable from: 0.5.0-1~swh1~bpo10+1] ...
vsellier updated the task description for T3060: Deploy swh-search v0.6.0 in **staging**.
vsellier moved T3060: Deploy swh-search v0.6.0 in **staging** from Backlog to in-progress on the System administration board.
vsellier changed the status of T3060: Deploy swh-search v0.6.0 in **staging** from Open to Work in Progress.
swh-search: activate metrics
vsellier added a comment to T3042: swh-search: add statsd/prometheus metrics.
The dashboard was moved to the system directory: the new url is https://grafana.softwareheritage.org/goto/uBHBojEGz
vsellier added a comment to T3042: swh-search: add statsd/prometheus metrics.
swh-search:v0.5.0 deployed in all the environments, the metrics are correctly gathered by prometheus.
Let's create a real dashboard now [1]
vsellier requested review of D5104: swh-search: activate metrics.
vsellier added a revision to T3042: swh-search: add statsd/prometheus metrics: D5104: swh-search: activate metrics.