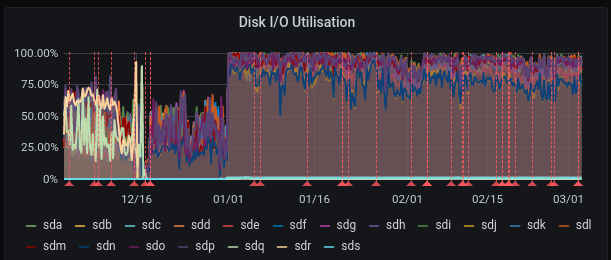
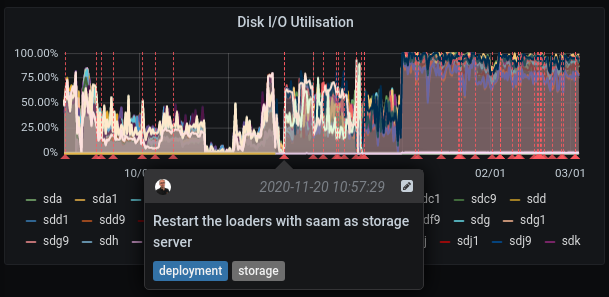
Several defaults were detected on the zfs pool on belvedere this night (2021-03-03) (P965)
This is the current pool status :
root@belvedere:~# zpool status -v data
pool: data
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://zfsonlinux.org/msg/ZFS-8000-8A
scan: scrub repaired 0B in 0 days 03:14:42 with 33 errors on Wed Mar 3 03:38:44 2021
remove: Removal of vdev 3 copied 1.23T in 5h35m, completed on Tue Dec 15 19:28:52 2020
88.3M memory used for removed device mappings
config:
NAME STATE READ WRITE CKSUM
data DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
wwn-0x50000397bc8969c1 ONLINE 0 0 0
wwn-0x50000396dc8a2191 ONLINE 0 0 0
mirror-1 DEGRADED 0 0 0
wwn-0x500003965c898904 DEGRADED 0 0 12 too many errors
wwn-0x500003965c898910 DEGRADED 0 0 12 too many errors
mirror-5 DEGRADED 0 0 0
wwn-0x50000396dc8a2161 DEGRADED 0 0 46 too many errors
wwn-0x500003972c8a44d1 DEGRADED 0 0 46 too many errors
mirror-6 ONLINE 0 0 0
wwn-0x50000396dc8a2185 ONLINE 0 0 8
wwn-0x50000397bc8969b1 ONLINE 0 0 8
mirror-7 ONLINE 0 0 0
wwn-0x5002538c409a8258 ONLINE 0 0 0
wwn-0x5002538c40ba6713 ONLINE 0 0 0
mirror-8 ONLINE 0 0 0
wwn-0x5002538c409a825a ONLINE 0 0 0
wwn-0x5002538c40ba66ab ONLINE 0 0 0
mirror-9 ONLINE 0 0 0
wwn-0x5002538c409a8252 ONLINE 0 0 0
wwn-0x5002538c409a8256 ONLINE 0 0 0
mirror-10 ONLINE 0 0 0
wwn-0x5002538c40ba6716 ONLINE 0 0 0
wwn-0x5002538c409a8253 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
/srv/softwareheritage/postgres/11/indexer/base/16406/774467031.317
/srv/softwareheritage/postgres/11/indexer/base/16406/774467031.180
/srv/softwareheritage/postgres/11/indexer/base/16406/774467031.110
/srv/softwareheritage/postgres/11/indexer/base/16406/774467031.316(more information on a previous identical issue on T2892)