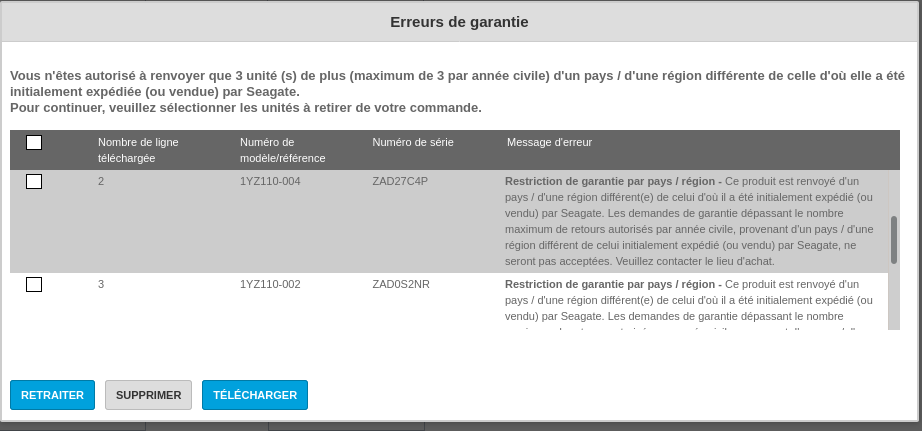
esnode3 is ready to be migrated :
❯ curl -s http://192.168.100.63:9200/_cat/allocation\?v\&s\=node 09:09:53
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node
4397 4.4tb 4.4tb 2.3tb 6.7tb 65 192.168.100.61 192.168.100.61 esnode1
4397 4.4tb 4.4tb 2.3tb 6.7tb 65 192.168.100.62 192.168.100.62 esnode2
0 0b 5.9gb 5.4tb 5.4tb 0 192.168.100.63 192.168.100.63 esnode3