Related: D746
Details
Details
- Reviewers
douardda zack ardumont - Group Reviewers
Reviewers - Maniphest Tasks
- T1384: Document indexer architecture / metadata pipeline
- Commits
- rDCIDX55e039cad540: Explain in text what each metadata indexer does.
rDCIDX1153c57d9e9b: Document the metadata workflow.
Diff Detail
Diff Detail
- Repository
- rDCIDX Metadata indexer
- Lint
Automatic diff as part of commit; lint not applicable. - Unit
Automatic diff as part of commit; unit tests not applicable.
Event Timeline
Comment Actions
Build is green
See https://jenkins.softwareheritage.org/job/DCIDX/job/tox/86/ for more details.
Comment Actions
You need to make the "assets" make target available for the main doc process to build your images.
See https://forge.softwareheritage.org/source/swh-model/browse/master/docs/Makefile and https://forge.softwareheritage.org/source/swh-model/browse/master/docs/Makefile.local
Comment Actions
In your sequence diagram, it looks strange that you try to retrieve existing metadata from the "Graph Storage", but you upload newly created metadata (in the alt box) only to the "Indexer Storage"
| docs/metadata_workflow.rst | ||
|---|---|---|
| 7–9 ↗ | (On Diff #2336) | This part of the description is unclear w.r.t the sequence diagram. How is this "deduplication" implemented? |
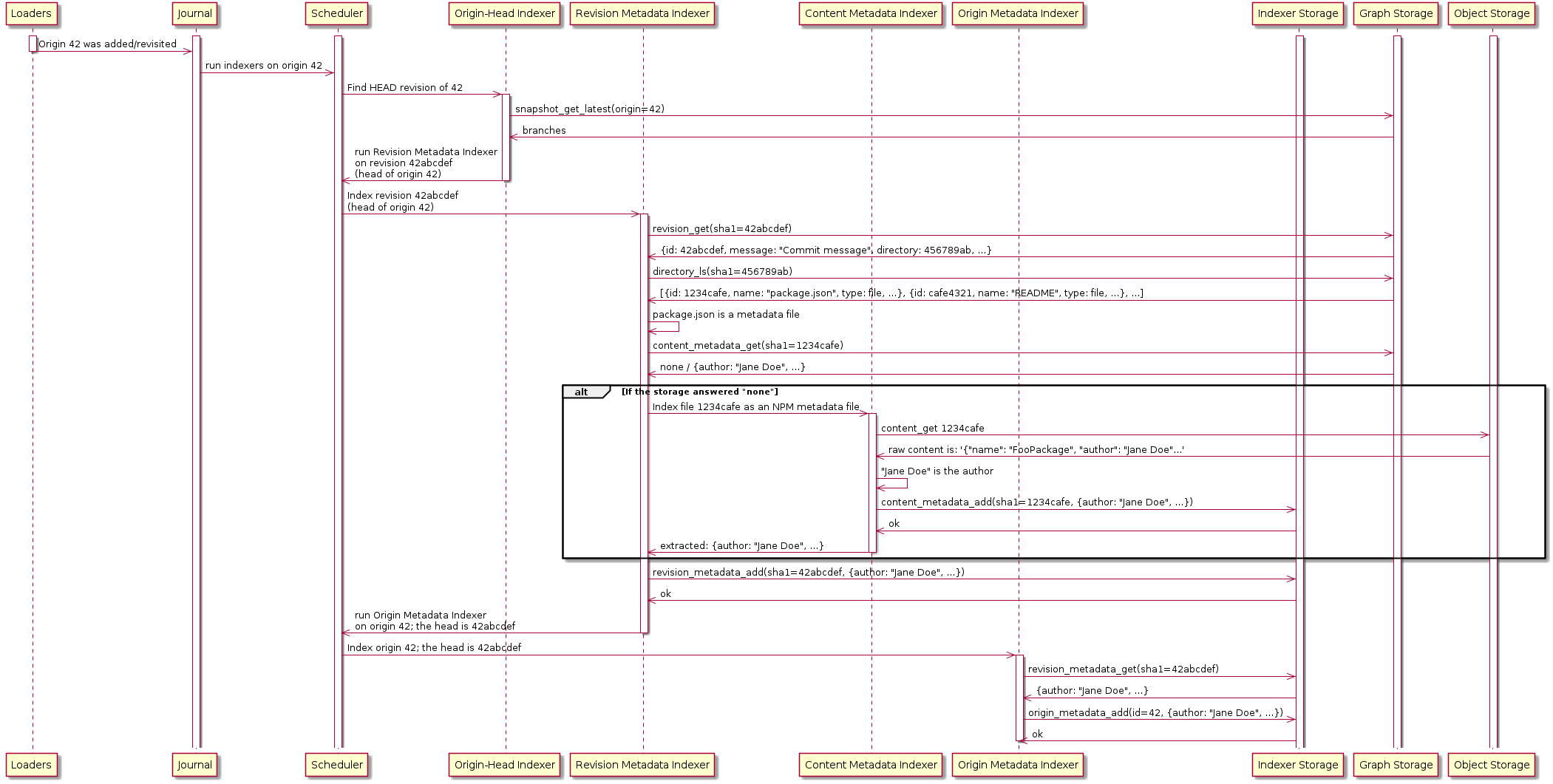
Comment Actions
Indeed, thanks.
| docs/metadata_workflow.rst | ||
|---|---|---|
| 7–9 ↗ | (On Diff #2336) | When the "alt" block is not executed. The work is deduplicated, not the data itself. |
Comment Actions
Build is green
See https://jenkins.softwareheritage.org/job/DCIDX/job/tox/104/ for more details.
Comment Actions
Build is green
See https://jenkins.softwareheritage.org/job/DCIDX/job/tox/105/ for more details.
| docs/index.rst | ||
|---|---|---|
| 15 | nitpick: we usually use dashes as filename separator for doc files, please favor that over the underscore here | |
| docs/metadata_workflow.rst | ||
| 4 ↗ | (On Diff #2379) | We should clarify which kind of metadata we are talking about here. In the past with @moranegg we have agreed on the following terminology:
You should consider starting this document documenting this distinction. Failing that (e.g., because we want to document the distinction properly elsewhere), you should at least stick to the terminology of intrinsic metadata in the documentation, because it's the workflow about them that you are documenting, not the other one. |
| docs/metadata_workflow.rst | ||
|---|---|---|
| 4 ↗ | (On Diff #2379) | Good point, will do. |
Comment Actions
- Rename metadata_workflow.rst -> metadata-workflow.rst
- Mention this doc is about intrinsic metadata only, for now.
Comment Actions
Build was aborted
Link to build: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/109/
See console output for more information: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/109/console
Comment Actions
Build was aborted
Link to build: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/110/
See console output for more information: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/110/console
Comment Actions
| docs/images/tasks-metadata-indexers.uml | ||
|---|---|---|
| 47 |
pretty sure what the thanks means but hey ;) Explicitely content_metadata_get is a call from the indexer_storage api. So: IDX_REV_META->>IDX_STORAGE | |
Comment Actions
Build is green
See https://jenkins.softwareheritage.org/job/DCIDX/job/tox/125/ for more details.
| docs/images/tasks-metadata-indexers.uml | ||
|---|---|---|
| 47 | Did you comment on an old version of that Diff? | |
| docs/images/tasks-metadata-indexers.uml | ||
|---|---|---|
| 47 | Apparently so | |
Comment Actions
Build is green
See https://jenkins.softwareheritage.org/job/DCIDX/job/tox/238/ for more details.
Comment Actions
Build has FAILED
Link to build: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/239/
See console output for more information: https://jenkins.softwareheritage.org/job/DCIDX/job/tox/239/console