- renaming methods filter_contents to filter and index_content to index
in all sub-classes and orchestrator
- renaming dependencies to ContentIndexer instead of BaseIndexer
- renaming in tests
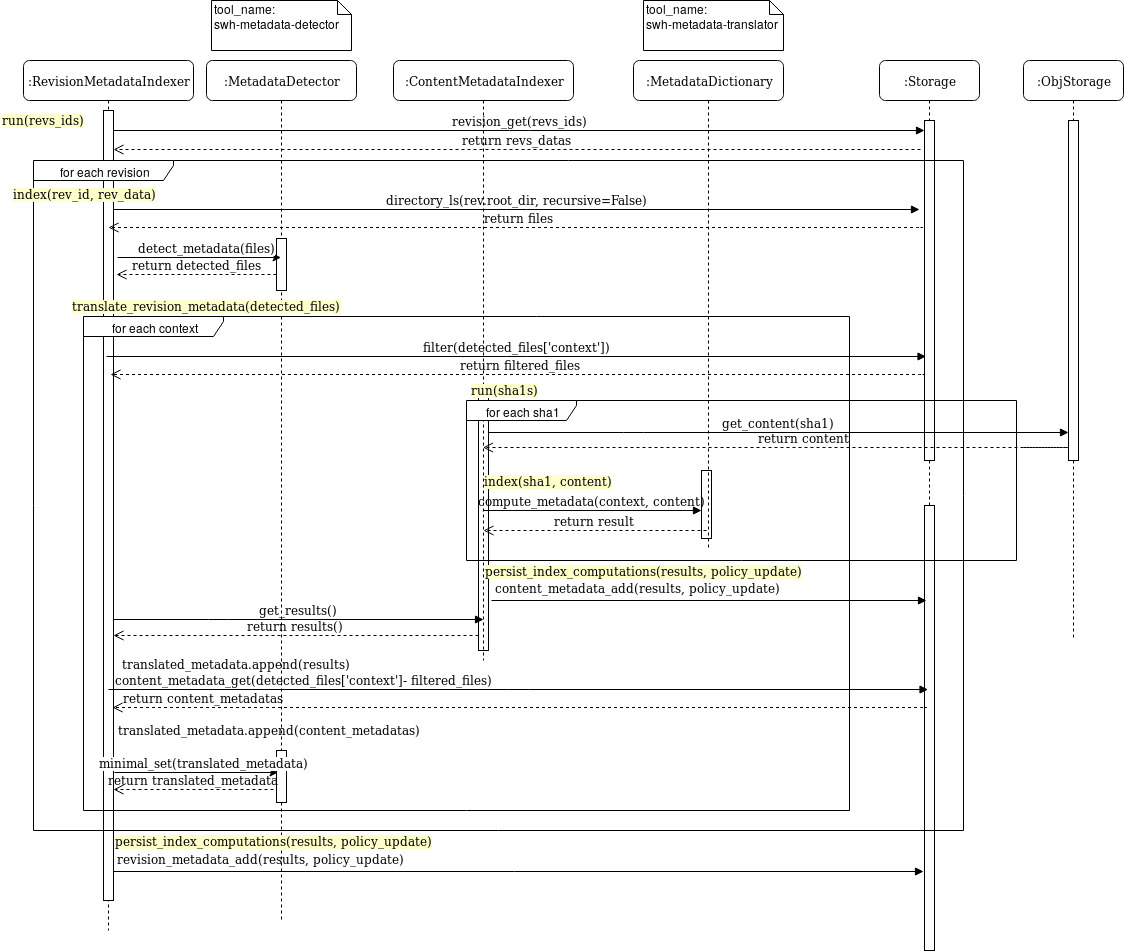
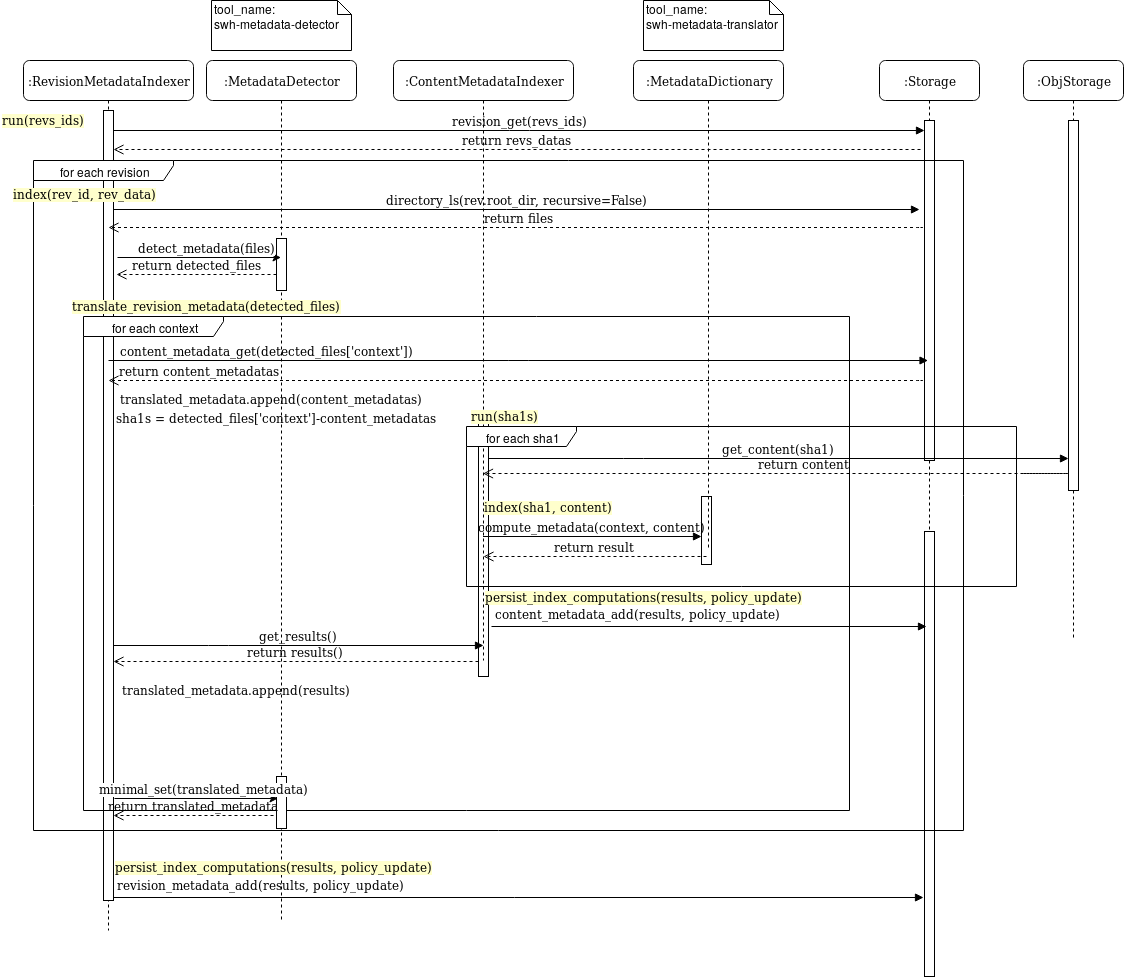
Added RevisionMetadataIndexer with a detection tool for metadata
- RevisionMetadataIndexer takes a list of revisions and detects
in the root directory all the file names supported by the
swh-metadata-detector version 0.0.1 that can contain metadata
- checks if files where translated before in the content_metadata
table
- if not: sends the files to indexation
- aggregates results
resolves T738
Note: should keep results in revision_metadata but this part
is not ready in the storage
- also, changed init of ContentMetadataIndexer with tool in args
Updated documentation with new revision indexer