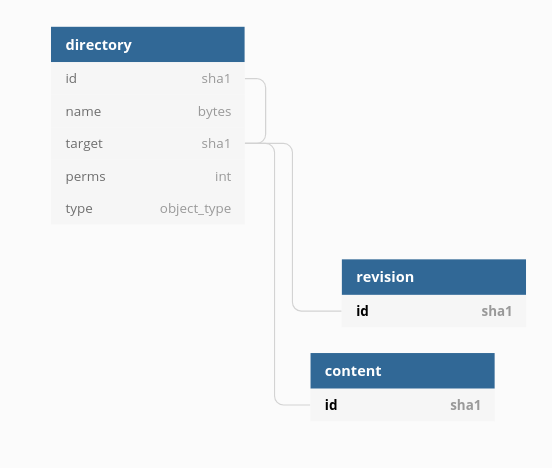
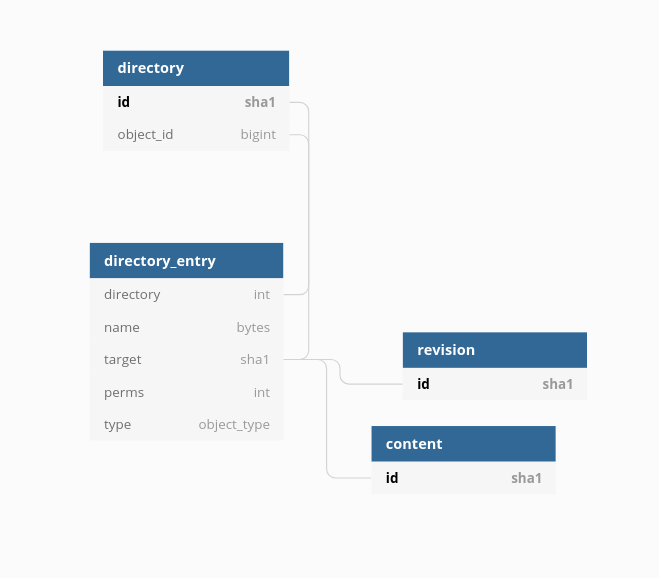
The current SQL storage represents directory with two (groups of) tables: one for directory nodes (linking them to directory entries) and three tables for directory entries and their attributes.
The join between the directory table and the directory entry ones is a massive pain, due to the size of the involved tables (see: P766).
We would like to experiment with more "flattened" layouts for the SQL representation of directories, that reduce or eliminate the need for such a join.
Experimentation should benchmark storage size and access speed, for both one-off and batch access.