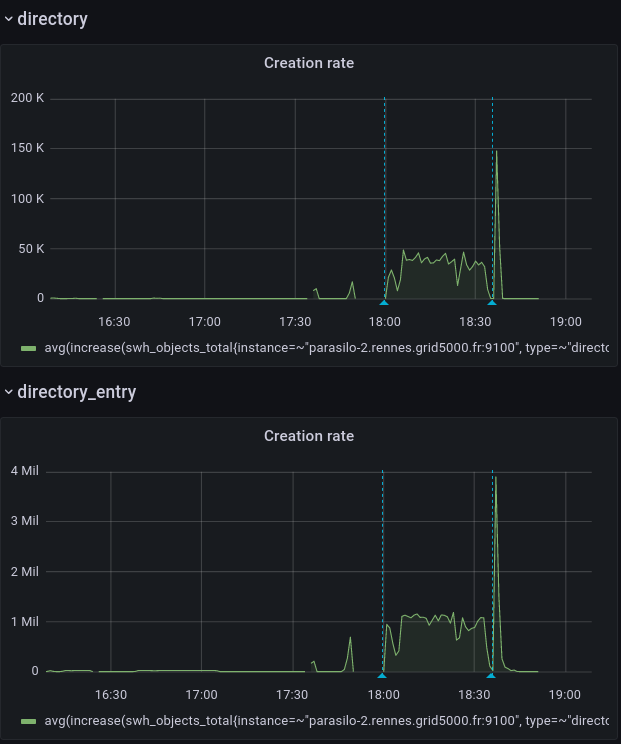
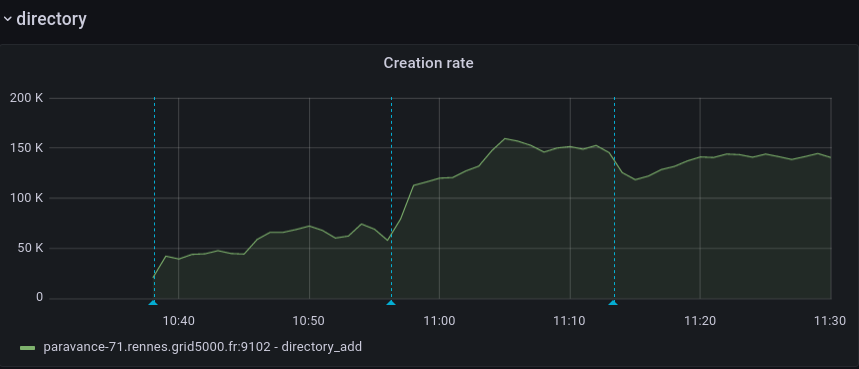
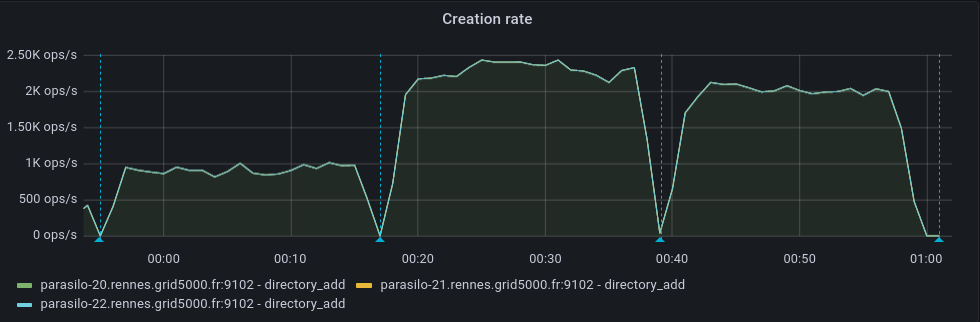
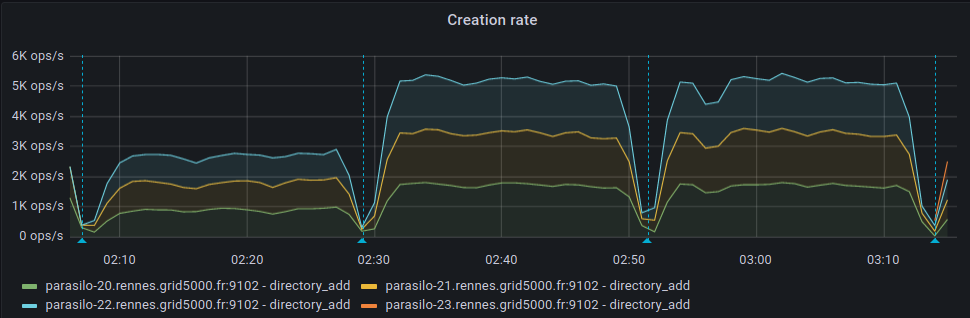
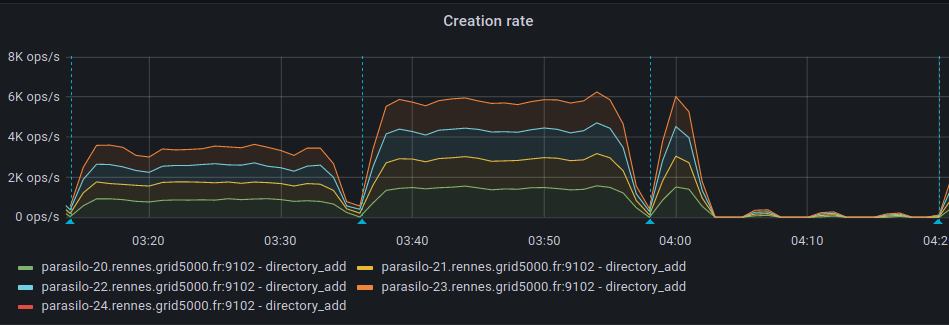
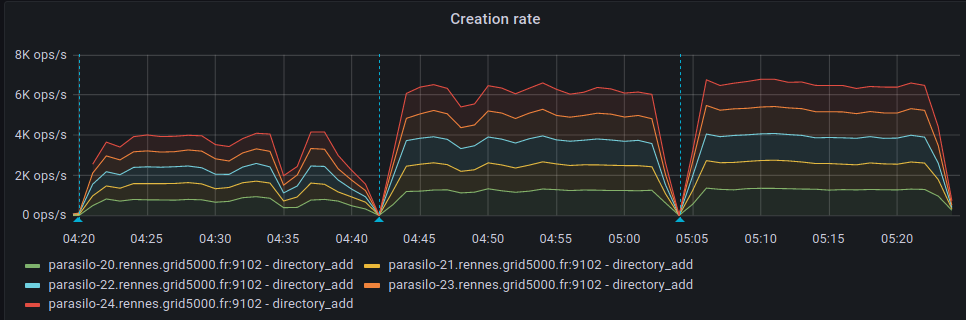
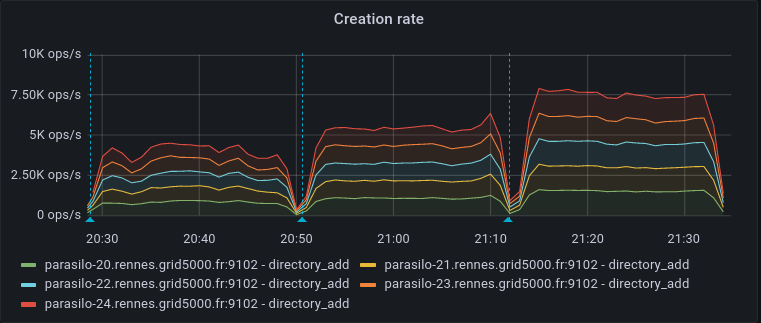
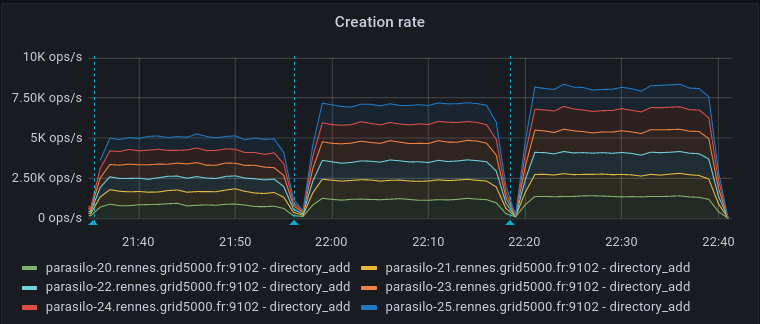
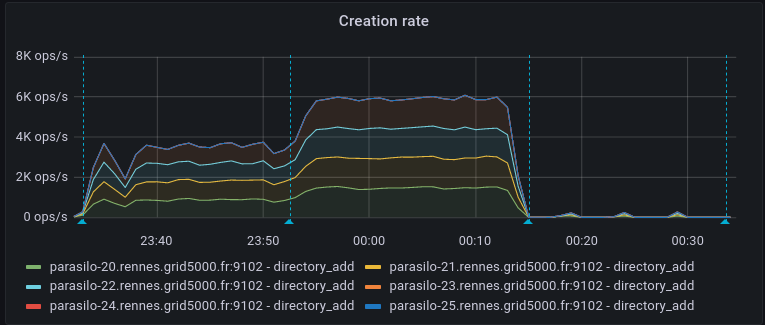
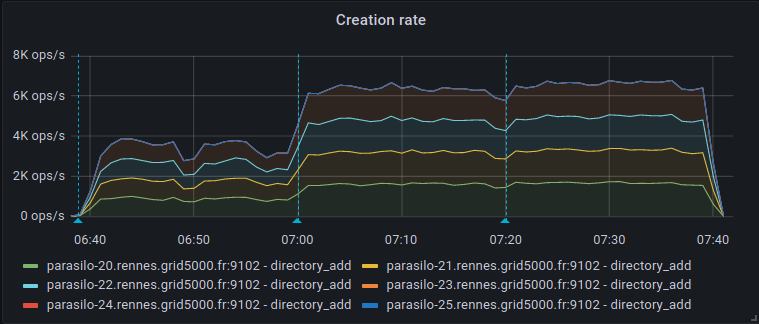
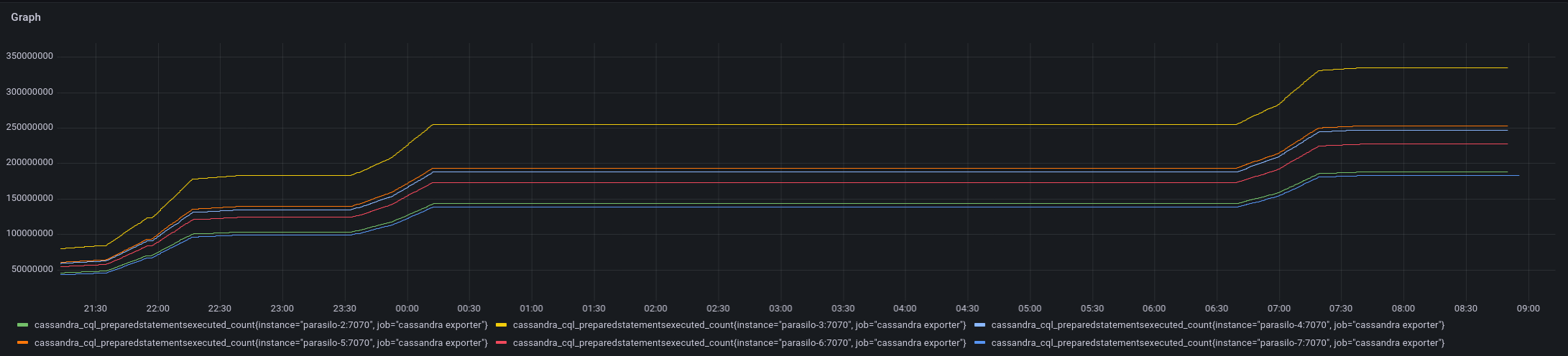
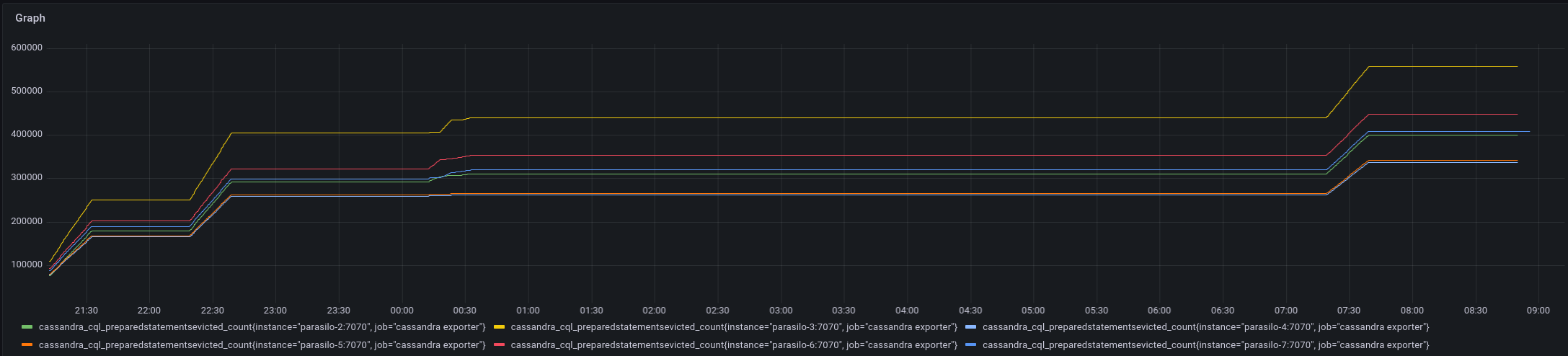
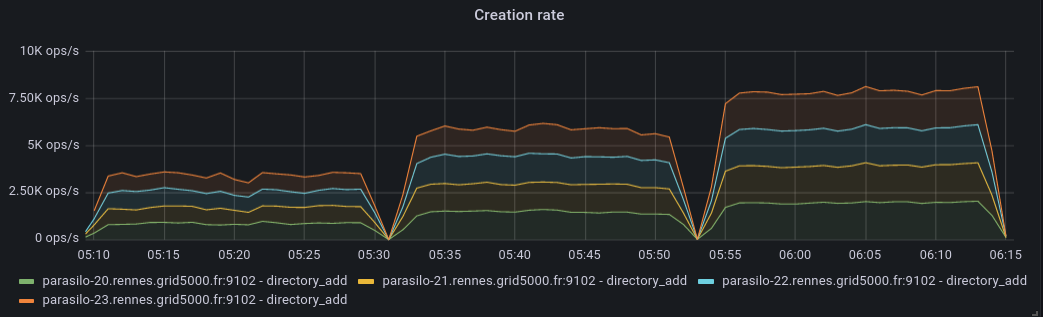
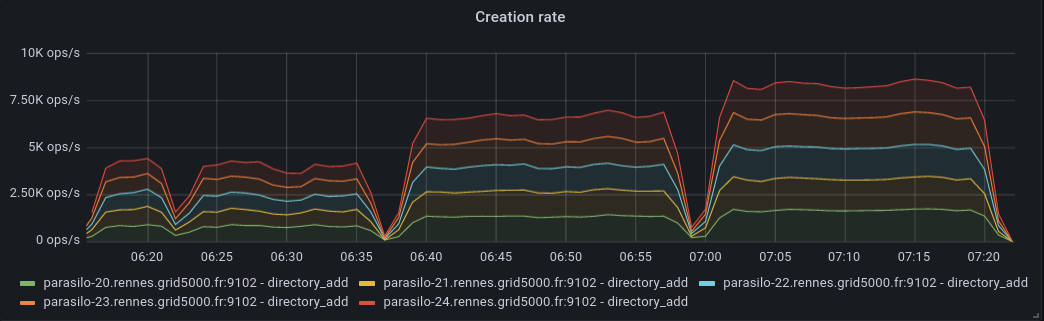
This adds a new config option for the cassandra backend,
'directory_entries_insert_algo', with three possible values:
- 'one-per-one' is the default, and preserves the current naive behavior
- 'concurrent' and 'batch' are attempts at being more efficient
Addresses the current performance bottleneck, according to T3493#68979