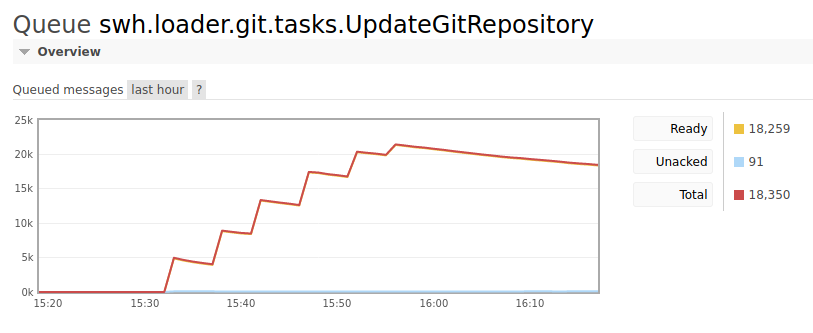
The scheduler takes some time to schedule new origins.
It's now more apparent since we added some more workers to consume the standard git
queue [1]. It was a bit apparent with the gitlab.com origins (still lagging but less
than earlier [2])
[1] T3825: the queue is now drained completely but the scheduler takes too much time to
fill it.
[2] still 409k origins lag (vs 3M at first) with an apparent plateau around the
01/01/2022 - https://grafana.softwareheritage.org/goto/hNSnn-Ank?orgId=1