Complete proposal for the above solution:
Feed Advanced Search
Oct 1 2021
Oct 1 2021
vlorentz changed the status of T3552: Fix corrupted releases, revisions, and directories in the storage from Open to Work in Progress.
Sep 24 2021
Sep 24 2021
Sep 23 2021
Sep 23 2021
vlorentz renamed T3552: Fix corrupted releases, revisions, and directories in the storage from Fix corrupted releases and revisions in the storage to Fix corrupted releases, revisions, and directories in the storage.
vlorentz triaged T3607: Document consistency guarantees of the loaders with respect to the storage as Normal priority.
Sep 22 2021
Sep 22 2021
vlorentz added a comment to T3596: Support "weird" permissions in directories.
vlorentz added a comment to T3595: Support disordered directory entries in git.
Complete proposal to implement the above solution:
vlorentz updated the task description for T3586: Figure out what to do with 'misordered' directories in Cassandra.
vlorentz closed T3582: cassandra: Use 'git ordering' for directory entries, a subtask of T3585: Fix inconsistencies of the Cassandra backend with postgres, as Wontfix.
Heh actually that's not an issue, the directory_get_entries documentation does not guarantee an order.
vlorentz updated the task description for T3594: Faithfully store weird git objects.
vlorentz added a comment to T3596: Support "weird" permissions in directories.
Possible solution: store them as an ascii string instead of an integer.
vlorentz added a comment to T3595: Support disordered directory entries in git.
Possible solution: store a rank along with each directory entry, but ignore it unless we are reconstructing a git object or computing a SWHID (v1?)
vlorentz updated the task description for T3595: Support disordered directory entries in git.
Sep 20 2021
Sep 20 2021
Sep 17 2021
Sep 17 2021
vlorentz updated the task description for T3586: Figure out what to do with 'misordered' directories in Cassandra.
vlorentz removed a project from T3586: Figure out what to do with 'misordered' directories in Cassandra: meta-task.
vlorentz placed T3586: Figure out what to do with 'misordered' directories in Cassandra up for grabs.
vlorentz triaged T3586: Figure out what to do with 'misordered' directories in Cassandra as Normal priority.
vlorentz triaged T3585: Fix inconsistencies of the Cassandra backend with postgres as Normal priority.
Sep 16 2021
Sep 16 2021
changing the status to resolved as the main issues are solved.
Other tests with more parallel workers will be launched, if other problems will be detected, they will be tracked in new dedicated tickets.
vsellier closed T3493: [cassandra] Git loader performance are very bad, a subtask of T3357: Perform some tests of the cassandra storage on Grid5000, as Resolved.
Sep 15 2021
Sep 15 2021
vlorentz updated the task description for T3010: Enable the validating storage proxy in production.
vsellier updated the task description for T3577: Parallel loaders performances .
vsellier updated the task description for T3357: Perform some tests of the cassandra storage on Grid5000.
vsellier added a comment to T3573: [cassandra] directory and content read benchmarks.
Test of a the new D6269 patch:
vsellier added a comment to T3573: [cassandra] directory and content read benchmarks.
2 flame graphs of the previous directory_ls:
- one-by-one
first run (cache cold):
{kind=link}
vsellier added a comment to T3573: [cassandra] directory and content read benchmarks.
This is the results of the different runs:
vsellier added a comment to T3573: [cassandra] directory and content read benchmarks.
vsellier renamed T3573: [cassandra] directory and content read benchmarks from [cassandra] directory and content read benchmarkss to [cassandra] directory and content read benchmarks.
vsellier changed the status of T3573: [cassandra] directory and content read benchmarks from Open to Work in Progress.
Sep 13 2021
Sep 13 2021
vsellier closed T3465: Test multidatacenter replication, a subtask of T3357: Perform some tests of the cassandra storage on Grid5000, as Resolved.
vsellier added a comment to T3465: Test multidatacenter replication.
The new datacenter is active since a couple of week.
It allowed to test:
- how to declare a new dc and bootstrap it
- how the data is replicated between the DC
- how to perform inter/intra DC repairs
- how to add nodes on a DC on bootstrap it
- how to remove a datacenter
vsellier closed T3464: Prepare a quote for the cassandra servers, a subtask of T3357: Perform some tests of the cassandra storage on Grid5000, as Resolved.
The quote is done and validated, we will launch the command when the new matinfo deal will be available
Sep 10 2021
Sep 10 2021
vlorentz added a parent task for T3552: Fix corrupted releases, revisions, and directories in the storage: T887: Vault: "snapshot" cooker.
Sep 8 2021
Sep 8 2021
vlorentz closed T2590: Finish the indexer -> swh-search pipeline, a subtask of T1117: Origin search is *slow* when you look for very common words, as Resolved.
vlorentz closed T2590: Finish the indexer -> swh-search pipeline, a subtask of T2182: Switch production swh-web to use swh-search instead of postgresql search., as Resolved.
Sep 3 2021
Sep 3 2021
vlorentz placed T3552: Fix corrupted releases, revisions, and directories in the storage up for grabs.
vlorentz triaged T3552: Fix corrupted releases, revisions, and directories in the storage as Normal priority.
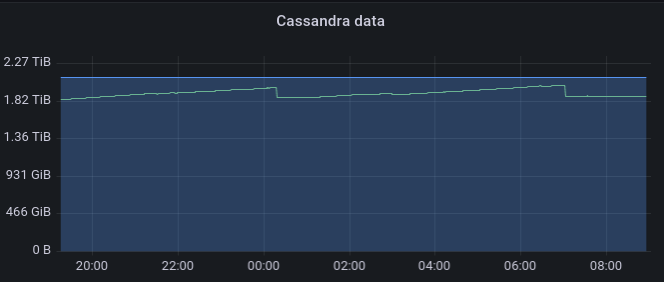
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
With the new concurrent replay of the directory, the disk usage grow up rapidly:
vlorentz closed T3018: Allow querying raw_extrinsic_metadata by hash in swh-storage, a subtask of T2703: Use intrinsic identifiers/hashes for RawExtrinsicMetadata objects, as Resolved.
Aug 31 2021
Aug 31 2021
Aug 30 2021
Aug 30 2021
vsellier closed T3517: [cassandra] decorate the method calls to have statsd metrics , a subtask of T3357: Perform some tests of the cassandra storage on Grid5000, as Resolved.
vsellier changed the status of T3539: snapshot/metadata inversion in origin_visit_status_get_random from Open to Work in Progress.
Aug 27 2021
Aug 27 2021
vsellier added a comment to T3465: Test multidatacenter replication.
New cluster state after all the reservation are up:
vsellier@gros-50:~$ nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.16.97.3 1.4 TiB 256 60.1% a3ae5fa2-c063-4890-87f1-bddfcf293bde rack1 UN 172.16.97.6 1.4 TiB 256 60.0% bfe360f1-8fd2-4f4b-a070-8f267eda1e12 rack1 UN 172.16.97.5 1.39 TiB 256 59.9% 478c36f8-5220-4db7-b5c2-f3876c0c264a rack1 UN 172.16.97.4 1.4 TiB 256 59.9% b3105348-66b0-4f82-a5bf-31ef28097a41 rack1 UN 172.16.97.2 1.4 TiB 256 60.1% de866efd-064c-4e27-965c-f5112393dc8f rack1
vsellier added a comment to T3465: Test multidatacenter replication.
- cassandra stopped
vsellier@fnancy:~/cassandra$ seq 50 64 | parallel -t ssh root@gros-{} systemctl stop cassandra- data cleaned
vsellier@fnancy:~/cassandra$ seq 50 64 | parallel -t ssh root@gros-{} "rm -rf /srv/cassandra/*"- Cassandra restarted
vsellier@fnancy:~/cassandra$ seq 50 64 | parallel -t ssh root@gros-{} systemctl start cassandravsellier added a comment to T3465: Test multidatacenter replication.
well after reflection, it will be probably faster to recreate the second DC from scractch now the configuration is ready.
vsellier added a comment to T3465: Test multidatacenter replication.
5 nodes were added on the cluster:
- configuration pushed on g5k, disk reserved for 14 days on the new servers, a new reservation was launched with the new nodes
- each node was started one by one after their status was UN on the nodetool status output
Datacenter: DC1 =============== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack DN 172.16.97.3 ? 256 0.0% a3ae5fa2-c063-4890-87f1-bddfcf293bde r1 DN 172.16.97.6 ? 256 0.0% bfe360f1-8fd2-4f4b-a070-8f267eda1e12 r1 DN 172.16.97.5 ? 256 0.0% 478c36f8-5220-4db7-b5c2-f3876c0c264a r1 DN 172.16.97.4 ? 256 0.0% b3105348-66b0-4f82-a5bf-31ef28097a41 r1 DN 172.16.97.2 ? 256 0.0% de866efd-064c-4e27-965c-f5112393dc8f r1
vsellier added a comment to T3465: Test multidatacenter replication.
10 nodes are not enough, I add 5 additional nodes to reduce the volume per node a little.
vsellier changed the status of T3517: [cassandra] decorate the method calls to have statsd metrics from Open to Work in Progress.
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
the lz4 compression was already activated by default. Changing the algo to zstd on the table snapshot was not really significant (initially with lz4: 7Go, zstd: 12Go, go back to lz4: 9Go :) )
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
interesting:
Depending on the data characteristics of the table, compressing its data can result in:
25-33% reduction in data size 25-35% performance improvement on reads 5-10% performance improvement on writes
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
The replaying is currently stopped as the data disks are now almost full.
I will try to activate the compression on some big tables to see if it can help.
I will probably need to start on small tables to recover some space before being able to compress the biggest tables
Aug 26 2021
Aug 26 2021
vsellier added a comment to T3465: Test multidatacenter replication.
These are the steps done to initialized the new cluster [1]:
- add a file datacenter-rackdc.properties on the server with the according DC
gros-50:~$ cat /etc/cassandra/cassandra-rackdc.properties dc=datacenter2 rack=rack1
- change the value of the properties endpoint_snitch from SimpleSnitch to GossipingPropertyFileSnitch [2].
The recommanded value for production is GossipingPropertyFileSnitch so it should have been this since the beginning
- configure the disk_optimization_strategy to ssd on the new datacenter
- update the seed_provider to have one node on each datacenter
- restart the datacenter1 nodes to apply the new configuration
- start the datacenter2 nodes one by one, wait until the status of the node is UN (Up and Normal) before starting another one (They can be stay in the UJ (joining) state for a couple of minutes)
- when done, update the swh keyspace to declare the replication strategy of the second DC
ALTER KEYSPACE swh WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3, 'datacenter2': 3};The replication of the new changes starts here but the full table contents need to be copied
- rebuild the cluster content:
vsellier@fnancy:~/cassandra$ seq 0 9 | parallel -t ssh gros-5{} nodetool rebuild -ks swh -- datacenter1The progression can be monitored with nodetool command:
gros-50:~$ nodetool netstats
Mode: NORMAL
Rebuild e5e64920-0644-11ec-92a6-31a241f39914
/172.16.97.4
Receiving 199 files, 147926499702 bytes total. Already received 125 files (62.81%), 57339885570 bytes total (38.76%)
swh/release-4 1082347/1082347 bytes (100%) received from idx:0/172.16.97.4
swh/content_by_blake2s256-2 3729362955/3729362955 bytes (100%) received from idx:0/172.16.97.4
swh/release-3 224510803/224510803 bytes (100%) received from idx:0/172.16.97.4
swh/content_by_blake2s256-1 240283216/240283216 bytes (100%) received from idx:0/172.16.97.4
swh/content_by_blake2s256-4 29491504/29491504 bytes (100%) received from idx:0/172.16.97.4
swh/release-2 6409474/6409474 bytes (100%) received from idx:0/172.16.97.4
...
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed Dropped
Large messages n/a 0 23 0
Small messages n/a 3 132753939 0
Gossip messages n/a 0 43915 0or to filter only running transfers:
gros-50:~$ nodetool netstats | grep -v 100%
Mode: NORMAL
Rebuild e5e64920-0644-11ec-92a6-31a241f39914
/172.16.97.4
Receiving 199 files, 147926499702 bytes total. Already received 125 files (62.81%), 57557961160 bytes total (38.91%)
swh/directory_entry-7 4819168032/4925484261 bytes (97%) received from idx:0/172.16.97.4
/172.16.97.2
Receiving 202 files, 111435975646 bytes total. Already received 139 files (68.81%), 60583670773 bytes total (54.37%)
swh/directory_entry-12 1631210003/2906113367 bytes (56%) received from idx:0/172.16.97.2
/172.16.97.6
Receiving 236 files, 186694443984 bytes total. Already received 142 files (60.17%), 58869656747 bytes total (31.53%)
swh/snapshot_branch-10 4449235102/7845572885 bytes (56%) received from idx:0/172.16.97.6
/172.16.97.5
Receiving 221 files, 143384473640 bytes total. Already received 132 files (59.73%), 58300913015 bytes total (40.66%)
swh/directory_entry-4 982247023/3492851311 bytes (28%) received from idx:0/172.16.97.5
Read Repair Statistics:
Attempted: 0
Mismatch (Blocking): 0
Mismatch (Background): 0
Pool Name Active Pending Completed Dropped
Large messages n/a 0 23 0
Small messages n/a 2 135087921 0
Gossip messages n/a 0 44176 0vsellier added a comment to T3465: Test multidatacenter replication.
The second cassandra cluster is finally up and synchronizing with the first one. The rebuild should be done by the end of the day or tomorrow.
vlorentz added a comment to T3493: [cassandra] Git loader performance are very bad.
D6139 should address the bottleneck in the flame graph
Aug 24 2021
Aug 24 2021
vsellier added a comment to T3493: [cassandra] Git loader performance are very bad.
Some live data from a git loader with a batch size of 1000 for each object types (with D6118 applied):
"object type";"input count";"missing_id duration (s)";"_missing_id count","_add duration(s)" content;1000;0.4928;999;35.3384 content;1000;0.4095;1000;34.1440 content;1000;0.4374;998;35.6249 content;492;0.2960;488;16.7028 directory;1000;0.3978;999;71.2518 directory;1000;0.4484;1000;39.6845 directory;1000;0.4356;1000;54.0077 directory;1000;0.3833;1000;36.1437 directory;1000;0.4319;1000;30.5690 directory;402;0.1718;402;19.2335 revision;1000;0.8671;1000;10.3417 revision;575;0.4639;575;4.0819
vsellier renamed T3493: [cassandra] Git loader performance are very bad from Git loader performance are very bad to [cassandra] Git loader performance are very bad.
Aug 23 2021
Aug 23 2021
vsellier added a comment to T3492: cassandra: origin_visit_add should increase next_visit_id even when upserting.
It seems the problem is no longer present now (tested with several origins)
root@parasilo-19:~/swh-environment/docker# docker exec -ti docker_swh-loader_1 bash
swh@8e68948366b7:/$ swh loader run git https://github.com/slackhq/nebula
INFO:swh.loader.git.loader.GitLoader:Load origin 'https://github.com/slackhq/nebula' with type 'git'
INFO:swh.loader.git.loader.GitLoader:Listed 293 refs for repo https://github.com/slackhq/nebula
{'status': 'uneventful'}
swh@8e68948366b7:/$ swh loader run git https://github.com/slackhq/nebula
INFO:swh.loader.git.loader.GitLoader:Load origin 'https://github.com/slackhq/nebula' with type 'git'
INFO:swh.loader.git.loader.GitLoader:Listed 293 refs for repo https://github.com/slackhq/nebula
{'status': 'uneventful'}
swh@8e68948366b7:/$ swh loader run git https://github.com/slackhq/nebula
INFO:swh.loader.git.loader.GitLoader:Load origin 'https://github.com/slackhq/nebula' with type 'git'
INFO:swh.loader.git.loader.GitLoader:Listed 293 refs for repo https://github.com/slackhq/nebula
{'status': 'uneventful'}vsellier added a comment to T3492: cassandra: origin_visit_add should increase next_visit_id even when upserting.
The origin_visit topic was replayed with your diff during the weekend. let's test now if the worker behavior is more deterministic
Aug 19 2021
Aug 19 2021
vlorentz added a comment to T3465: Test multidatacenter replication.
Starting with 10 nodes will allow to have some remaining space.
vlorentz added a comment to T3493: [cassandra] Git loader performance are very bad.
Can you try with this patch? P1118
vsellier changed the status of T3465: Test multidatacenter replication, a subtask of T3357: Perform some tests of the cassandra storage on Grid5000, from Open to Work in Progress.
vsellier changed the status of T3465: Test multidatacenter replication from Open to Work in Progress.
vsellier added a comment to T3465: Test multidatacenter replication.
The gros cluster at Nancy[1] has a lot of nodes(124) with small reservable SSD of 960Go. This can be a good candidate to create the second cluster. It will also allow to check the performance with data (and commit logs) on SSDs.
According to the main cluster, a minimum of 8 nodes are necessary to handle the volume of data (7.3 To and growing). Starting with 10 nodes will allow to have some remaining space.
vsellier added a comment to T3493: [cassandra] Git loader performance are very bad.
it seems some more precise information can be logged by activating the full query logs without a big performance impact: https://cassandra.apache.org/doc/latest/cassandra/new/fqllogging.html
vlorentz added a comment to T3491: Origin visit ids restart from 1 even if there is previous visits.
you mean T3492
vsellier added a comment to T3491: Origin visit ids restart from 1 even if there is previous visits.
Should be fixed by T3482
vlorentz triaged T3492: cassandra: origin_visit_add should increase next_visit_id even when upserting as Normal priority.
vsellier triaged T3491: Origin visit ids restart from 1 even if there is previous visits as Normal priority.
Aug 17 2021
Aug 17 2021
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
current status:
Aug 16 2021
Aug 16 2021
Aug 13 2021
Aug 13 2021
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
Current import status before the run of this week-end:
Aug 11 2021
Aug 11 2021
vsellier added a comment to T3357: Perform some tests of the cassandra storage on Grid5000.
The complete import is running almost continuously with 5 cassandra nodes since monday.