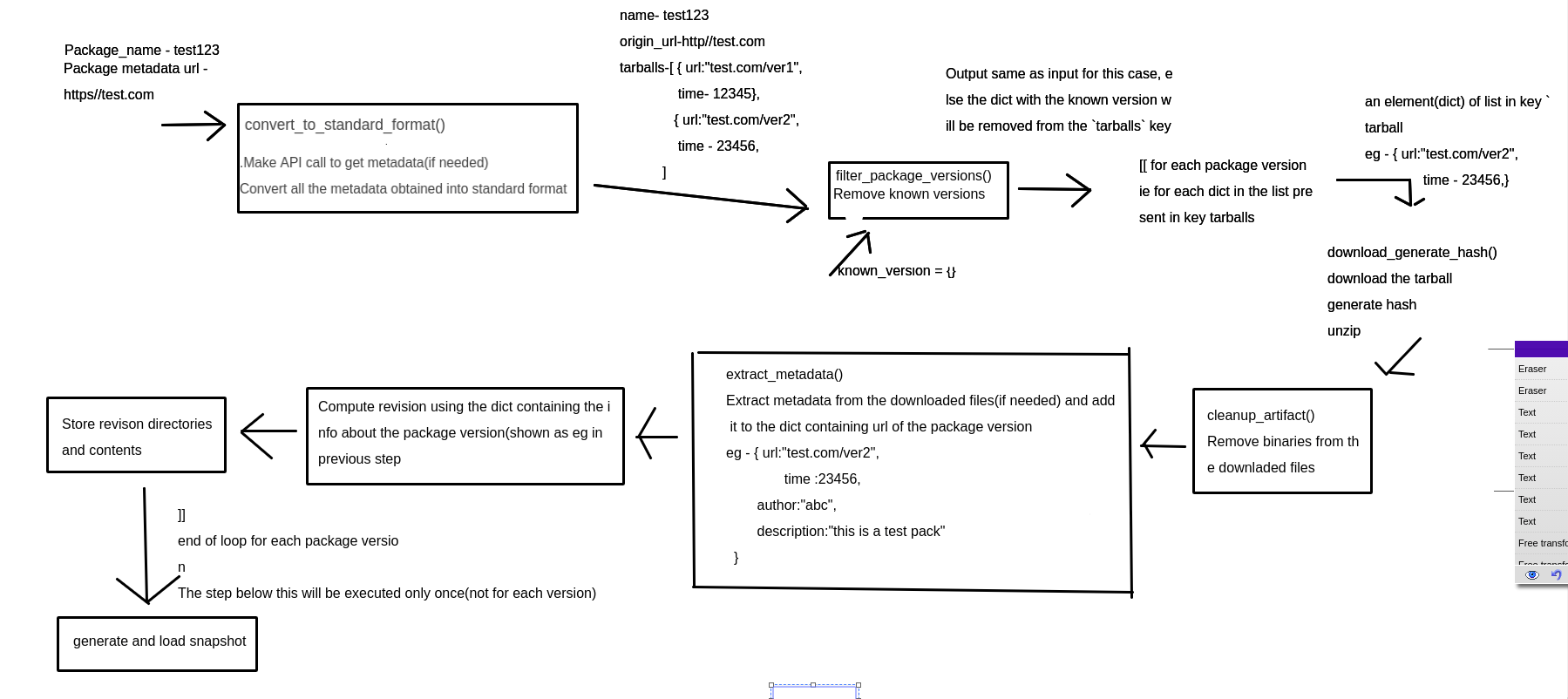
Implement methods to convert the metadata available for
each version of the focused package to a standard format.
The metadata of all the versions of a focused package can
either be passed by the lister or could be obtained by an API
call.
fetch_metadata() method can be overridden to get the
metadata of the focused package by the appropriate means
and convert it into a standard format.
Later, an origin is created by using the metadata provided
by the fetch_metadata() method.
Related T1389#31790
Closes T1389